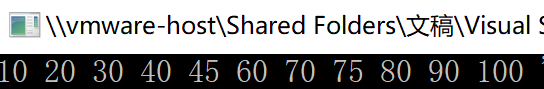希尔排序
原理:
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率
- 但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位
思路:
- 选择一个增量序列 t1,t2,……,tk,其中 ti > tj(i < j), tk = 1;
- 按增量序列个数 k,对序列进行 k 趟排序;
- 每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
图解希尔排序:

算法解析:
-
希尔排序是不稳定的,因为不同的间隔对应的数据是独自比较的,如果a=b,但是不在同一个间隔上,显然会出现前后颠倒的情况,所以希尔排序是不稳定的
-
平均性能优于直接插入排序
-
增量序列在希尔排序中是很重要的。一般好的增量序列都有2个共同的特征:
1. 最后一个增量必须为1,保证最后一趟是一次普通的插入排序;
2. 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况
C代码如下:
#include <stdio.h>
#include <stdlib.h>
void shellSort(int arr[], int length) {
int i, j, tmp;
//增量计算,计算间隔
int gap = length / 3 + 1;
while (gap >= 1) {
for (i = gap; i<length; i++) {
tmp = arr[i];
j = i - gap;
while (j >= 0 && arr[j] > tmp) {
arr[j + gap] = arr[j];
j -= gap;
}
arr[j + gap] = tmp;
}
if (gap == 1) {
break;
}
gap = gap / 3 + 1;
}
}
int main(){
int i;
int arr[] = { 70, 30, 40, 10, 80, 20, 90, 100, 75, 60, 45 };
int len = sizeof(arr) / sizeof(arr[0]);
shellSort(arr, len);
for (i = 0; i < len; i++)
{
printf("%d ", arr[i]);
}
system("pause");
return 0;
}
代码生成图