本文针对的是运行环境不到40G内存(不是GPU显存)的同学们,我的环境是白嫖版阿里云pai平台A10云主机(32G内存,24G显存)。
官方实际目前并没有发布8bit量化好的模型,github上发布的链接目前是个404(截止到20230802 14:45时仍然如此)

而要在线量化,根据官方回应需要至少是46G内存的环境,本来已经准备放弃,然而幸运的在huggingface上发现一位无名炼丹师发布的量化好的8bit版本
地址如下:https://huggingface.co/trillionmonster/Baichuan-13B-Chat-8bit
感谢好心人!!!
下载部署,按找说明启动,然后不出意外的报错了

看说明是少参数,再往上翻,发现在加载模型的阶段有提示

综上分析,当前模型,与量化版本当时引用的模型已经有调整,有参数变化,按提示应该是要在加载模型时指定版本,然而官网并没有模型的版本列表,量化作者也不知道,又陷入到僵局,这时候凭借资深搬砖人士的本能,手动补齐呗。
于是直接修改报错文件的代码,在本地huggingface的cache目录中,报错信息中有提示,看逻辑给个默认值0 就行了。
继续运行,于是报了另外一个错误

这回是user_token_id找不到,好吧,还得补,这回难点是:看命名这不是随便给个0或者1就行的,值对不上估计后面运行会出问题。
想到这是baichuan13b模型内的参数,要确定其初始值,还得回到官方的github上进行搜索,还真有问过类似问题:https://github.com/baichuan-inc/Baichuan-13B/issues/67 ,至此障碍扫清。
模型初始化代码片段如下
print("========= 开始初始化8bit量化模型")
print("========= 进行分词预处理")
tokenizer = AutoTokenizer.from_pretrained("trillionmonster/Baichuan-13B-Chat-8bit", use_fast=False, trust_remote_code=True)
print("========= 加载模型")
model = AutoModelForCausalLM.from_pretrained("trillionmonster/Baichuan-13B-Chat-8bit", device_map="auto", trust_remote_code=True)
print("========= 生成配置")
model.generation_config = GenerationConfig.from_pretrained("trillionmonster/Baichuan-13B-Chat-8bit")
model.generation_config.max_new_tokens=500
model.generation_config.user_token_id=195
model.generation_config.assistant_token_id=500
最后3行为补齐的参数,调整后,已经可以完成对话了
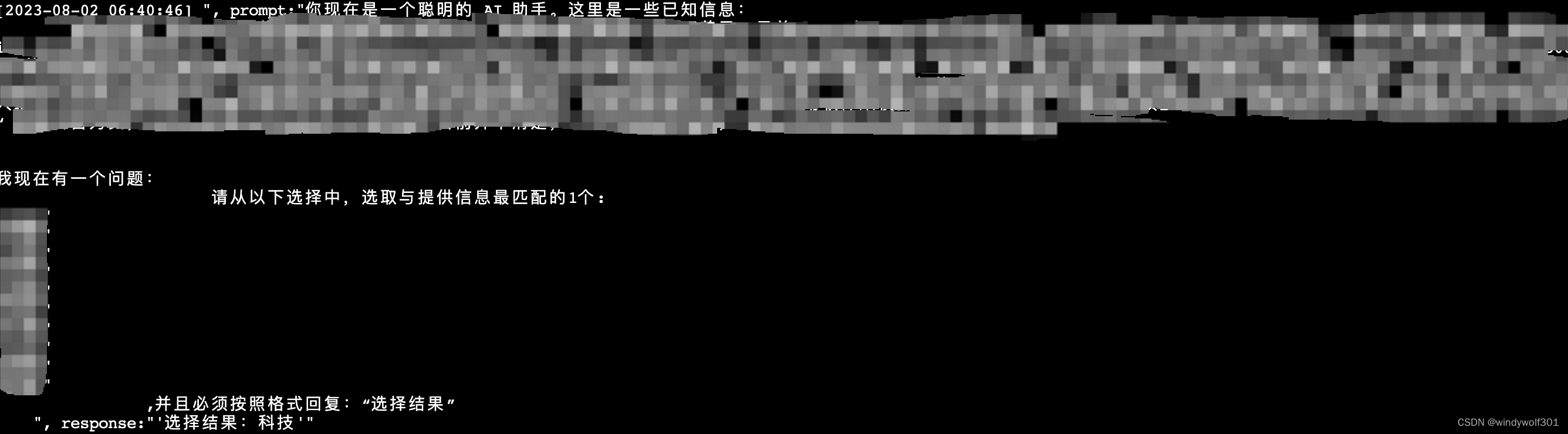
我的测试场景是给一段文字内容让模型进行限定分类范围的归类
顺便分享一个我参照chatglm2修改的api.py,用于支持http调用https://download.csdn.net/download/windywolf301/88148705