S2-MLPv2注意力机制
S2-MLPv2注意力是一种用于自然语言处理任务的注意力机制。它是在S2-MLP(Sparse-to-Dense Multi-Level Perceptron)模型的基础上进行改进的。
S2-MLPv2注意力的主要思想是使用多层感知机(MLP)来计算注意力权重,以捕捉输入序列中的重要信息。相比于传统的注意力机制,S2-MLPv2注意力在计算注意力权重时引入了非线性变换,从而提高了模型的表达能力。
论文地址:https://arxiv.org/pdf/2108.01072.pdf
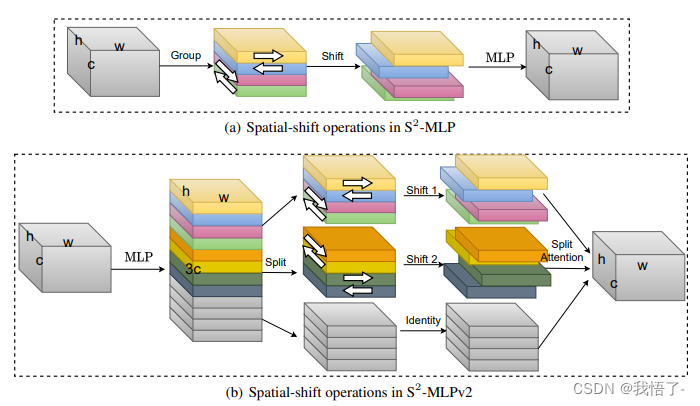
代码如下:
import numpy as np
import torch
from torch import nn
from torch.nn import init
# https://arxiv.org/abs/2108.01072
def spatial_shift1(x):
b,w,h,c = x.size()
x[:,1:,:,:c//4] = x[:,:w-1,:,:c//4]
x[:,:w-1,:,c//4:c//2] = x[:,1:,:,c//4:c//2]
x[:,:,1:,c//2:c*3//4] = x[:,:,:h-1,c//2:c*3//4]
x[:,:,:h-1,3*c//4:] = x[:,:,1:,3*c//4:]
return x
def spatial_shift2(x):
b,w,h,c = x.size()
x[:,:,1:,:c//4] = x[:,:,:h-1,:c//4]
x[:,:,:h-1,c//4:c//2] = x[:,:,1:,c//4:c//2]
x[:,1:,:,c//2:c*3//4] = x[:,:w-1,:,c//2:c*3//4]
x[:,:w-1,:,3*c//4:] = x[:,1:,:,3*c//4:]
return x
class SplitAttention(nn.Module):
def __init__(self,channel=512,k=3):
super().__init__()
self.channel=channel
self.k=k
self.mlp1=nn.Linear(channel,channel,bias=False)
self.gelu=nn.GELU()
self.mlp2=nn.Linear(channel,channel*k,bias=False)
self.softmax=nn.Softmax(1)
def forward(self,x_all):
b,k,h,w,c=x_all.shape
x_all=x_all.reshape(b,k,-1,c)
a=torch.sum(torch.sum(x_all,1),1)
hat_a=self.mlp2(self.gelu(self.mlp1(a)))
hat_a=hat_a.reshape(b,self.k,c)
bar_a=self.softmax(hat_a)
attention=bar_a.unsqueeze(-2)
out=attention*x_all
out=torch.sum(out,1).reshape(b,h,w,c)
return out
class S2Attention(nn.Module):
def __init__(self, channels=512 ):
super().__init__()
self.mlp1 = nn.Linear(channels,channels*3)
self.mlp2 = nn.Linear(channels,channels)
self.split_attention = SplitAttention()
def forward(self, x):
b,c,w,h = x.size()
x=x.permute(0,2,3,1)
x = self.mlp1(x)
x1 = spatial_shift1(x[:,:,:,:c])
x2 = spatial_shift2(x[:,:,:,c:c*2])
x3 = x[:,:,:,c*2:]
x_all=torch.stack([x1,x2,x3],1)
a = self.split_attention(x_all)
x = self.mlp2(a)
x=x.permute(0,3,1,2)
return x