文章目录
一、Adaptively Sparse Transformer
自适应稀疏变压器是变压器的一种。
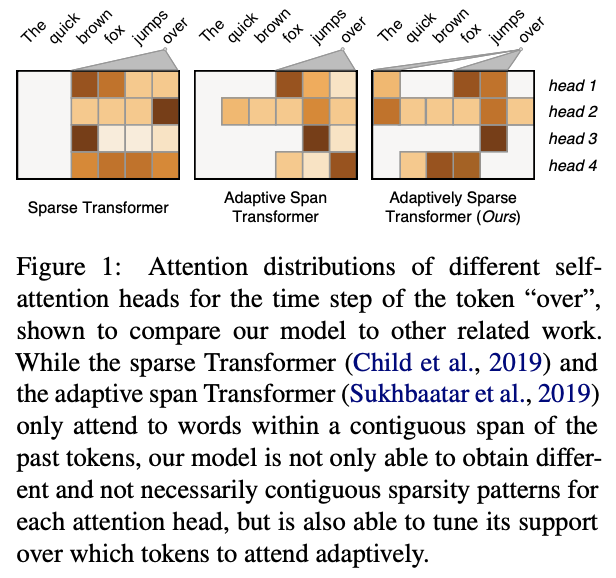
二、I-BERT
I-BERT 是 BERT 的量化版本,它使用纯整数算术来量化整个推理。 基于用于非线性运算的轻量级纯整数近似方法,例如 GELU、Softmax 和 Layer Normalization,它执行端到端纯整数 BERT 推理,无需任何浮点计算。
特别是,GELU 和 Softmax 使用轻量级二阶多项式进行近似,可以使用纯整数算术进行评估。 对于 LayerNorm,通过利用已知的平方根整数计算算法来执行仅整数计算。
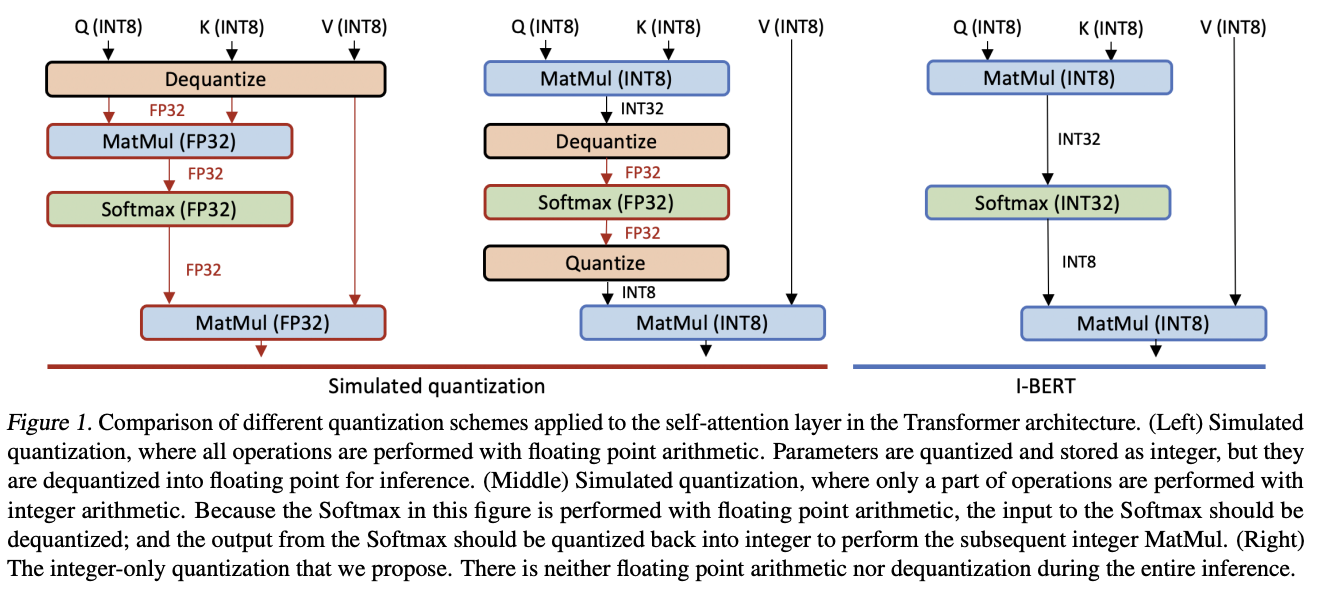
三、SqueezeBERT
SqueezeBERT 是 BERT 的一种高效架构变体,用于使用分组卷积的自然语言处理。 它很像 BERT-base,但具有以卷积形式实现的位置前馈连接层,以及许多层的分组卷积。
四、Feedback Transformer
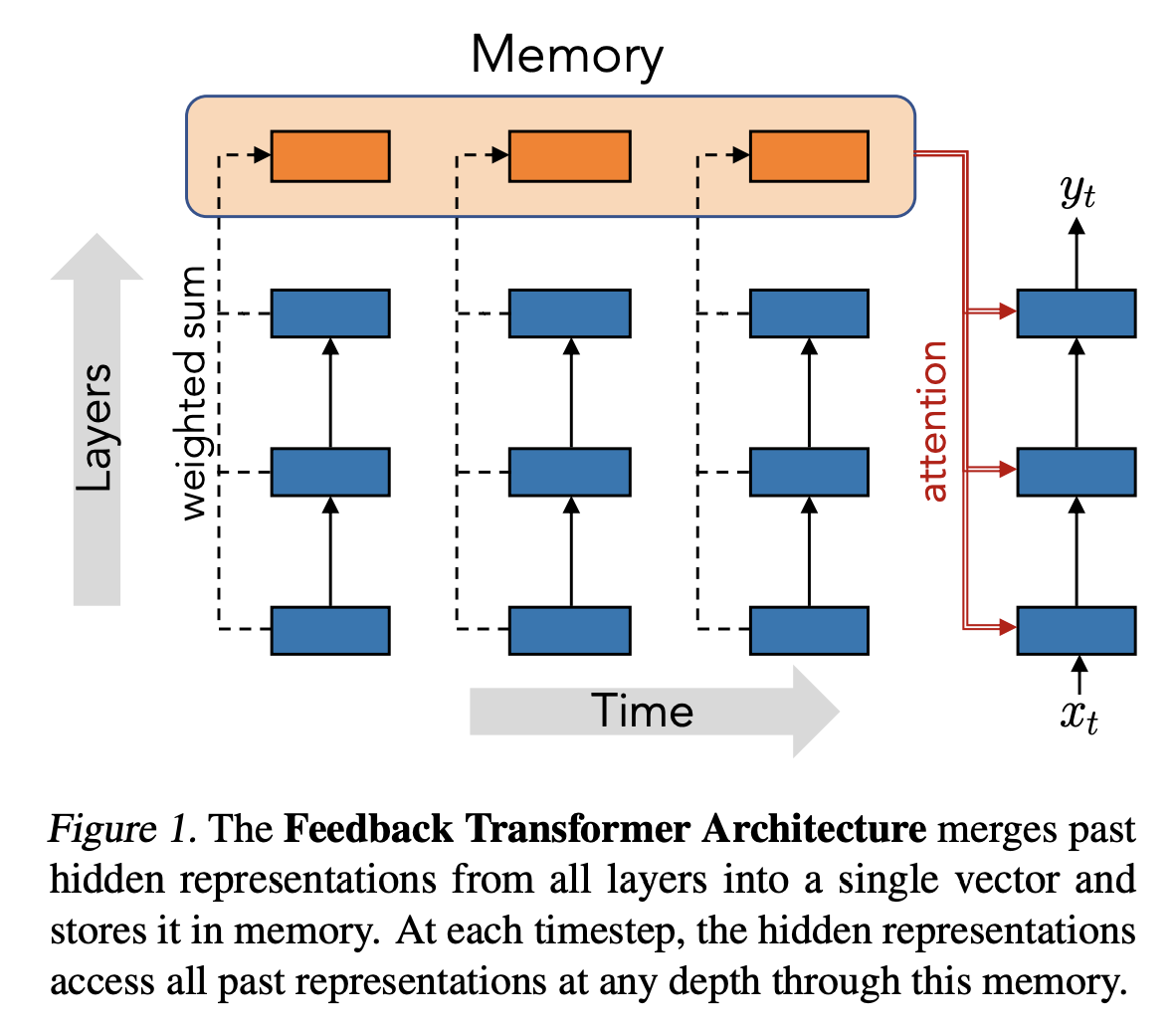
反馈变压器是一种顺序变压器,它将所有先前的表示暴露给所有未来的表示,这意味着当前时间步长的最低表示是由过去的最高级别抽象表示形成的。 这种反馈性质允许该架构执行递归计算,在先前的状态上迭代地构建更强的表示。 为了实现这一目标,标准 Transformer 的自注意力机制被修改,以便它关注更高级别的表示而不是较低的表示。
五、Sandwich Transformer
三明治变压器是变压器的一种变体,它对架构中的子层进行重新排序以实现更好的性能。 重新排序是基于作者的分析,即对底部有更多自注意力、对顶部有更多前馈子层的模型总体上往往表现更好。

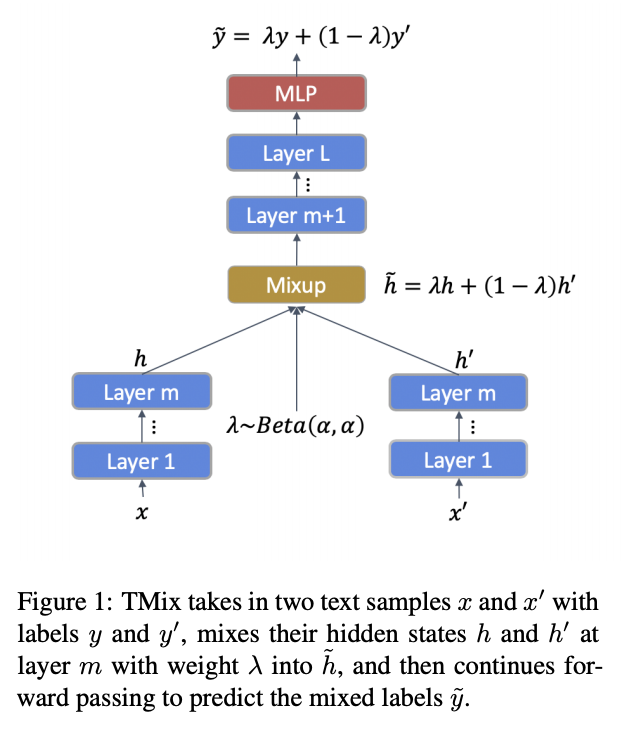
六、MixText
MixText 是一种用于文本分类的半监督学习方法,它使用一种称为 TMix 的新数据增强方法。 TMix 通过在隐藏空间中插入文本来创建大量增强训练样本。 该技术利用数据增强方面的进步来猜测未标记数据的低熵标签,使它们与标记数据一样易于使用。
七、ALDEN
ALDEN(即 Active Learning with DivErse iNterpretations)是一种用于文本分类的主动学习方法。 通过 DNN 中的局部解释,ALDEN 识别样本的线性可分离区域。 然后,它根据本地解释的多样性选择样本并查询它们的标签。
具体来说,我们首先计算 DNN 中每个样本的局部解释,作为从最终预测到输入特征的梯度反向传播。 然后,我们使用样本中最多样化的单词解释来衡量其多样性。 因此,我们选择具有最大不同解释的未标记样本进行标记,并使用这些标记样本重新训练模型。

八、Dual Contrastive Learning
对比学习通过在无监督环境中的自我监督在表征学习中取得了显着的成功。 然而,有效地将对比学习适应监督学习任务仍然是实践中的一个挑战。 在这项工作中,我们引入了一种双重对比学习(DualCL)框架,该框架可以同时学习同一空间中输入样本的特征和分类器的参数。 具体来说,DualCL 将分类器的参数视为与不同标签相关联的增强样本,然后利用输入样本和增强样本之间的对比学习。 对五个基准文本分类数据集及其低资源版本的实证研究证明了分类准确性的提高,并证实了 DualCL 学习判别表示的能力。