文章目录
一、Adaptive Span Transformer
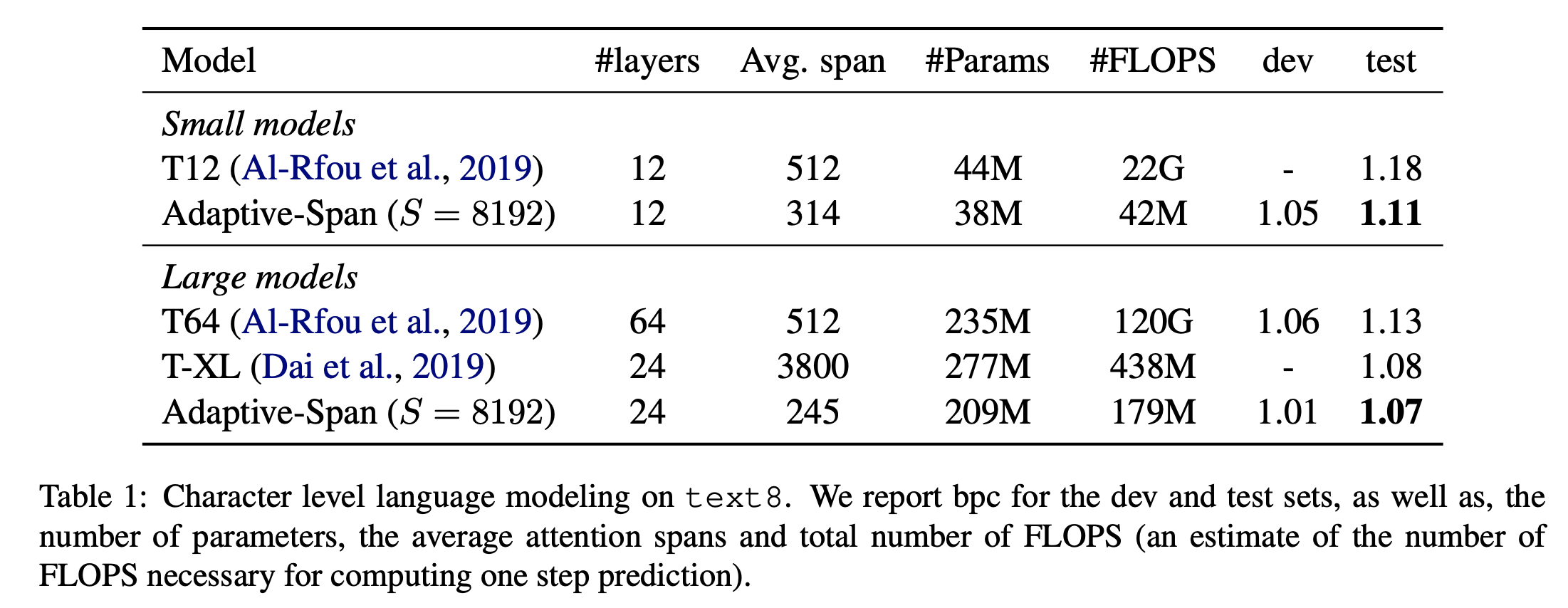
自适应注意力跨度变压器是一种利用称为自适应屏蔽的自注意力层改进的变压器,允许模型选择自己的上下文大小。 这会形成一个网络,其中每个注意力层都会收集有关其自身上下文的信息。 这允许扩展到超过 8k 个标记的输入序列。
他们的建议基于这样的观察:在传统 Transformer 的密集注意力下,每个注意力头共享相同的注意力跨度(参与完整的上下文)。 但许多注意力头可以专注于更局部的上下文(其他注意力头则关注更长的序列)。 这激发了对自注意力变体的需求,该变体允许模型选择自己的上下文大小(自适应屏蔽 - 请参阅组件)。
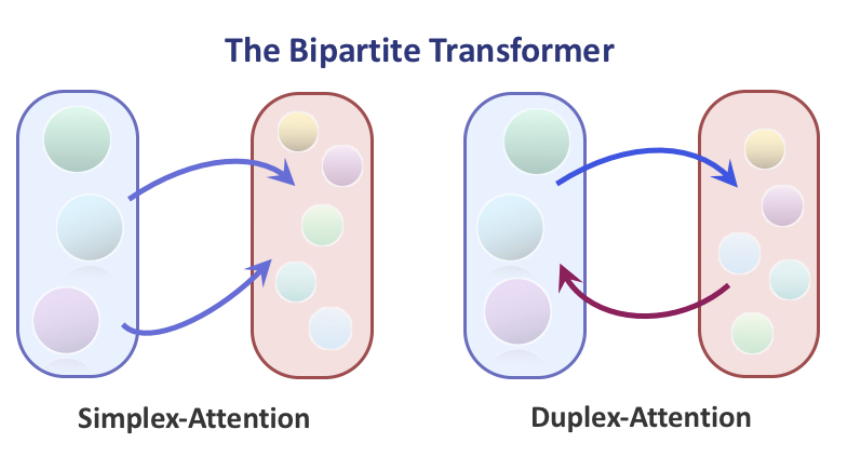
二、Generative Adversarial Transformer(GANformer)
GANformer 是一种新颖且高效的变压器,可用于视觉生成建模。 该网络采用二分结构,可以在图像上进行远程交互,同时保持线性效率的计算,可以轻松扩展到高分辨率合成。 它迭代地将信息从一组潜在变量传播到不断变化的视觉特征,反之亦然,以支持彼此的细化,并鼓励对象和场景的组合表示的出现。
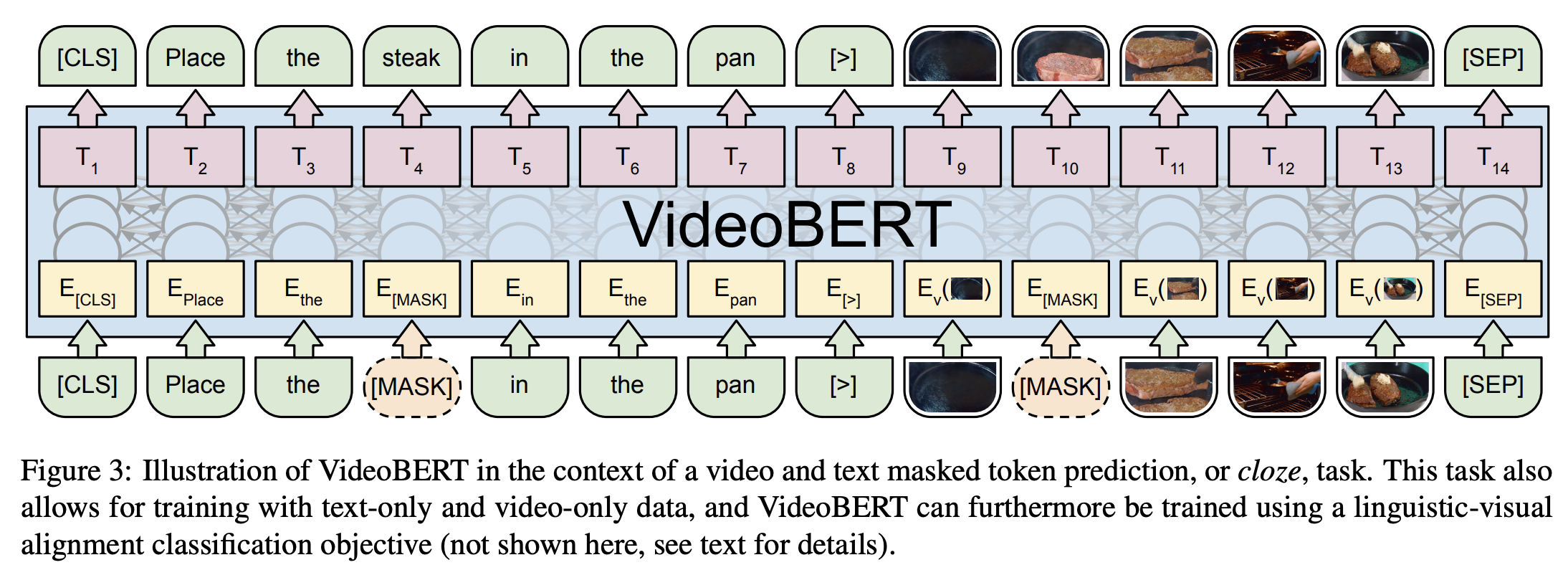
三、VideoBERT
VideoBERT 采用强大的 BERT 模型来学习视频的联合视觉语言表示。 它用于许多任务,包括动作分类和视频字幕。
四、Compressive Transformer
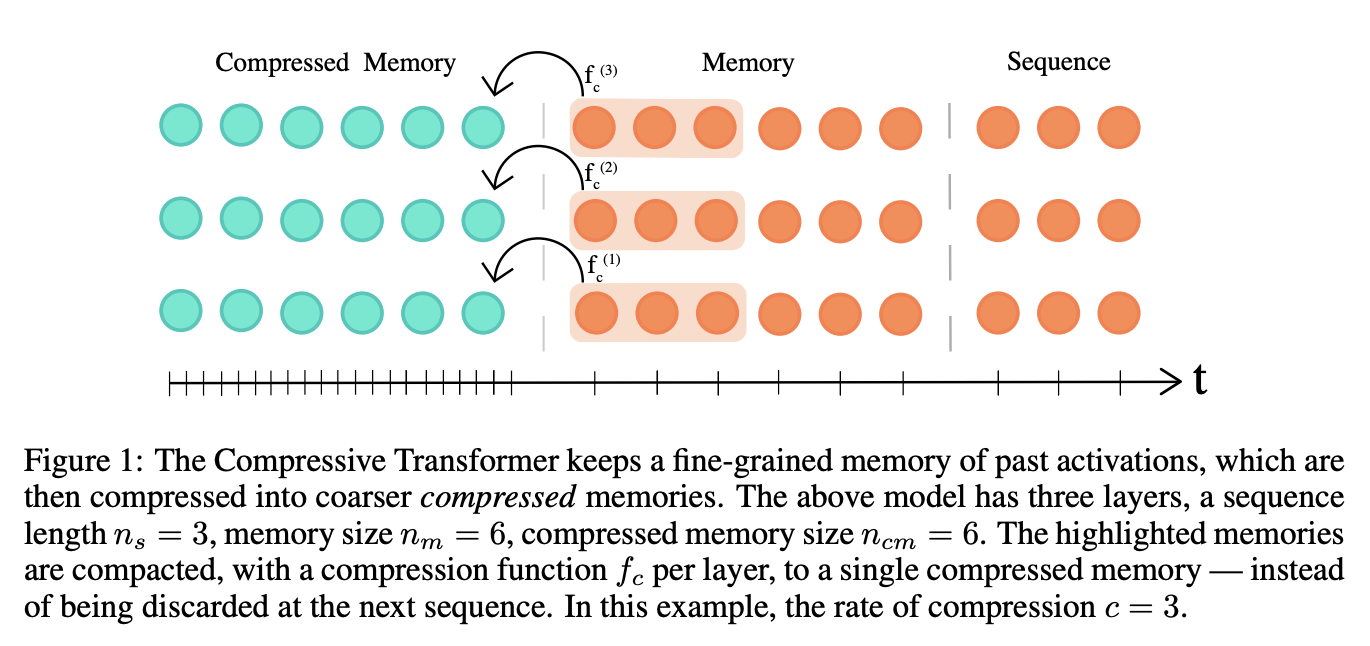
压缩变压器是变压器的扩展,它将过去的隐藏激活(记忆)映射到较小的压缩表示(压缩记忆)集。 压缩变压器对其记忆集和压缩记忆使用相同的注意力机制,学习查询其短期粒度记忆和长期粗略记忆。 它建立在 Transformer-XL 的思想之上,Transformer-XL 保留了每一层过去激活的记忆,以保留更长时间的上下文历史。 当过去的激活变得足够旧时(由内存大小控制),Transformer-XL 会丢弃它们。 压缩变压器的关键原理是压缩这些旧内存,而不是丢弃它们,并将它们存储在额外的压缩内存中。
在每个时间步,我们丢弃最旧的压缩存储器(FIFO),然后丢弃最旧的普通内存中的状态被压缩并转移到压缩内存中的新槽。 在训练期间,压缩记忆组件与主语言模型(单独的训练循环)分开进行优化。
五、Routing Transformer
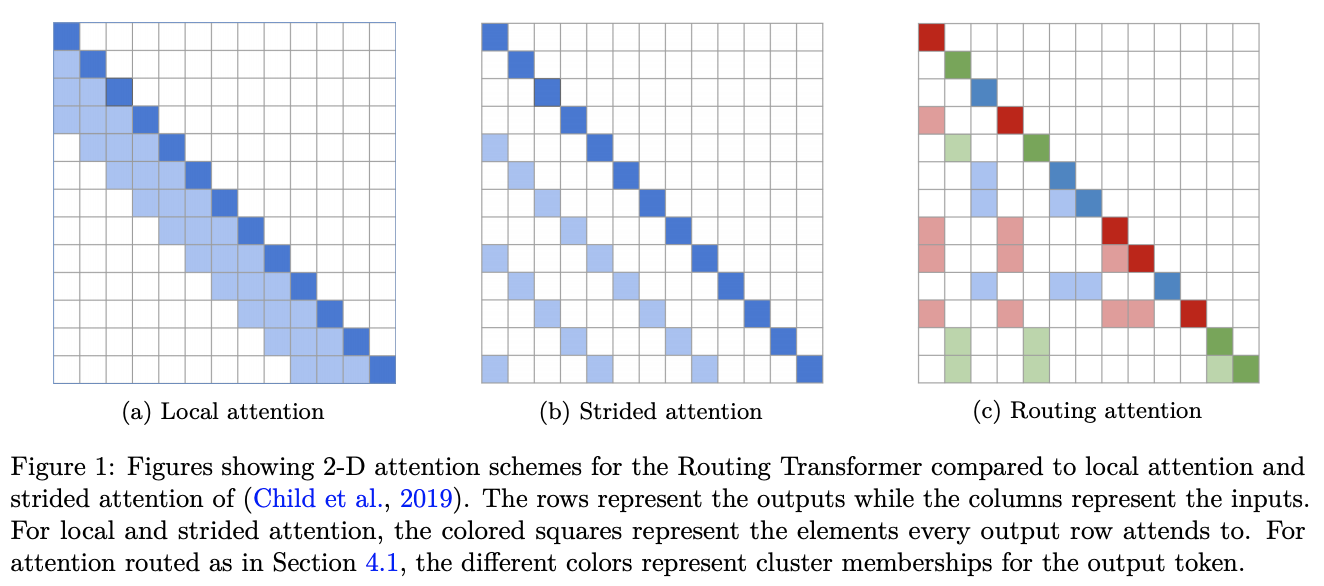
Routing Transformer是一个赋予self-attention基于在线k-means的稀疏路由模块的Transformer。 每个注意力模块都考虑空间的聚类:当前时间步仅关注属于同一聚类的上下文。 换句话说,当前时间步查询通过其集群分配路由到有限数量的上下文。
六、DeeBERT
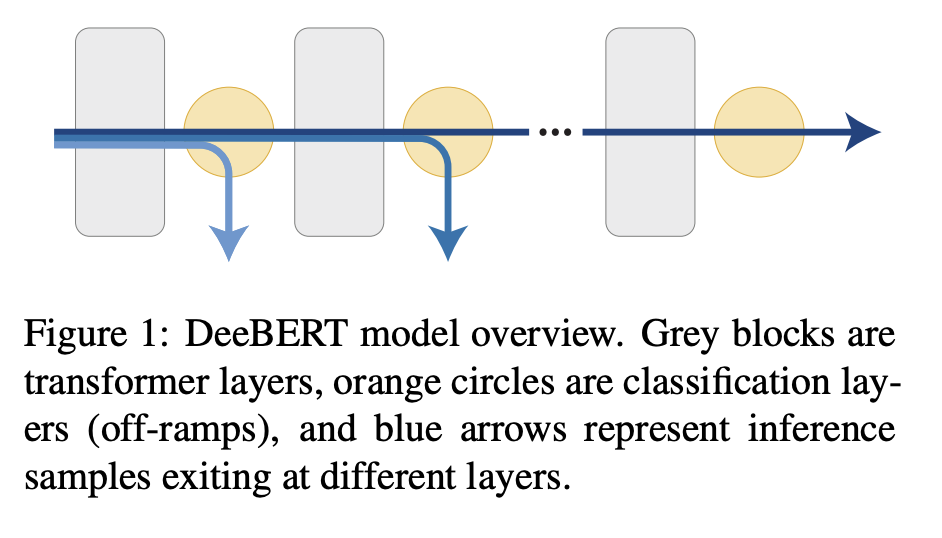
DeeBERT 是一种加速 BERT 推理的方法。 它在 BERT 的每个转换器层之间插入额外的分类层(称为出口)。 所有变压器层和出口匝道都在给定的下游数据集上联合微调。 在推理时,样本经过变压器层后,会被传递到下一个出口。 如果出口匝道对预测有信心,则返回结果; 否则,样本将被发送到下一个变压器层。
七、Table Pre-training via Execution(TAPEX)
TAPEX 是一种概念上简单、经验上强大的预训练方法,可以为现有模型提供表格推理技能。 TAPEX 通过在合成语料库上学习神经 SQL 执行器来实现表预训练,合成语料库是通过自动合成可执行 SQL 查询而获得的。
八、CuBERT
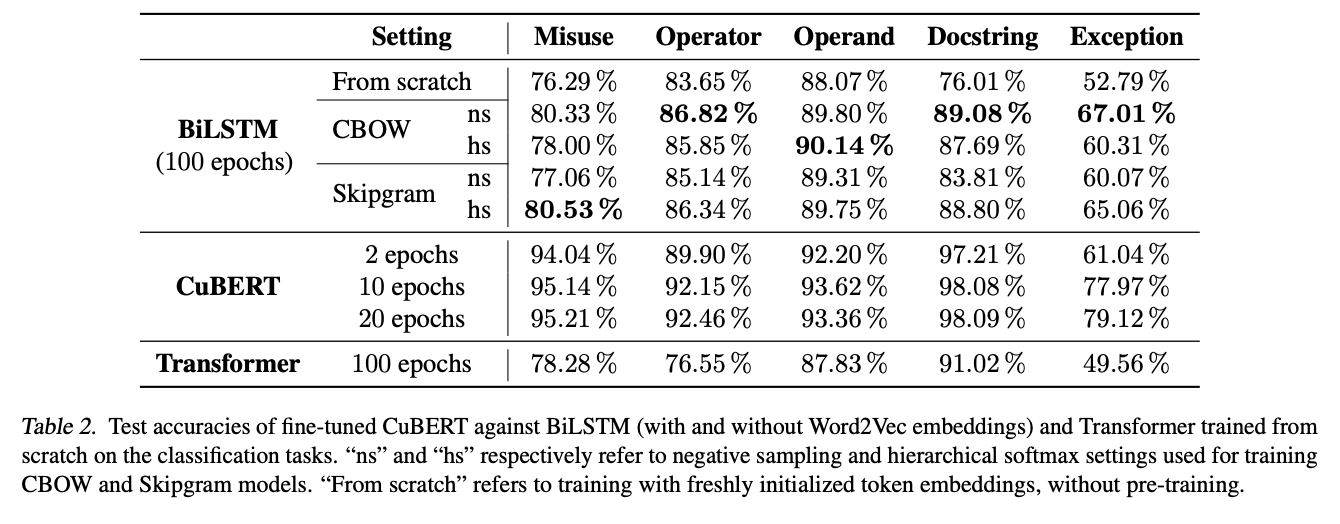
CuBERT,即代码理解 BERT,是一种基于 BERT 的代码理解模型。 为了实现这一目标,作者整理了从 GitHub 收集的大量 Python 程序语料库。 众所周知,GitHub 项目包含大量重复代码。 为了避免模型对此类重复代码产生偏差,作者使用 Allamanis (2018) 的方法执行重复数据删除。 生成的语料库包含 740 万个文件,总共 93 亿个标记(1600 万个唯一标记)。
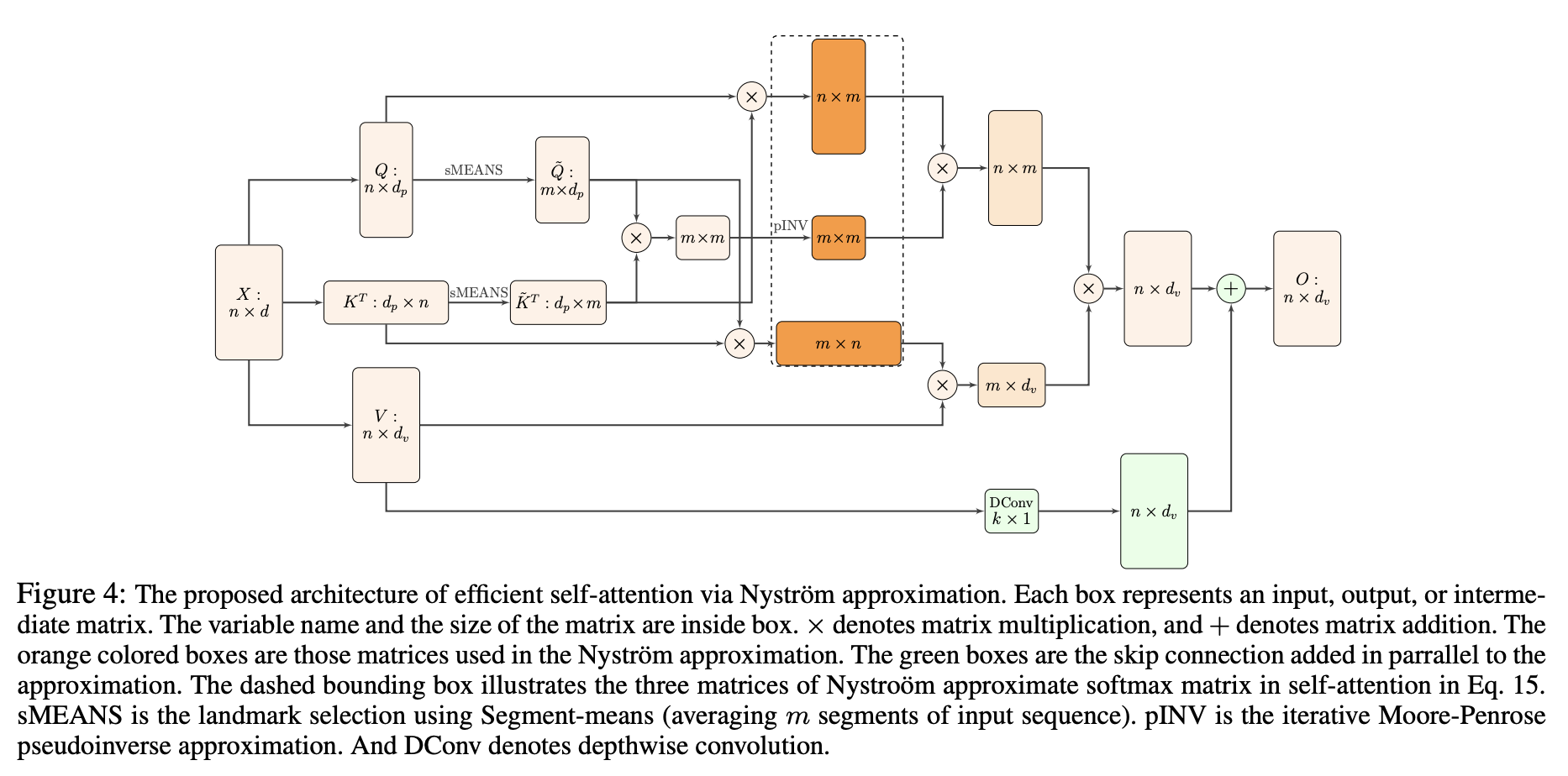
九、Nyströmformer
Nyströmformer 使用提出的 Nyström 近似替换了 BERT-small 和 BERT-base 中的自注意力。 这将自注意力复杂度降低到(O(n))并允许 Transformer 支持更长的序列。
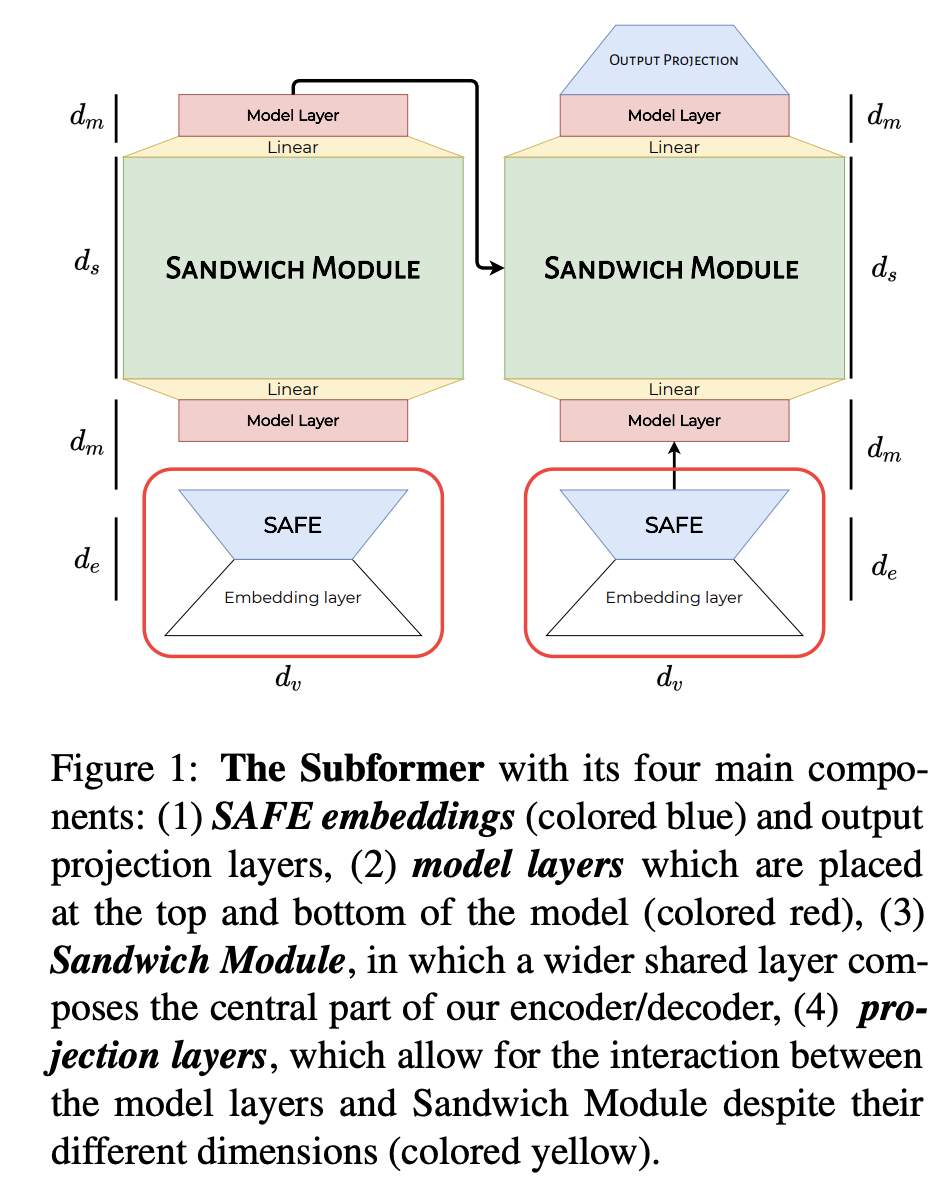
十、Subformer
Subformer 是一个结合了三明治式参数共享和自注意力嵌入分解(SAFE)的 Transformer,它克服了生成模型中朴素的跨层参数共享。 在 SAFE 中,使用一个小的自注意力层来减少嵌入参数数量。
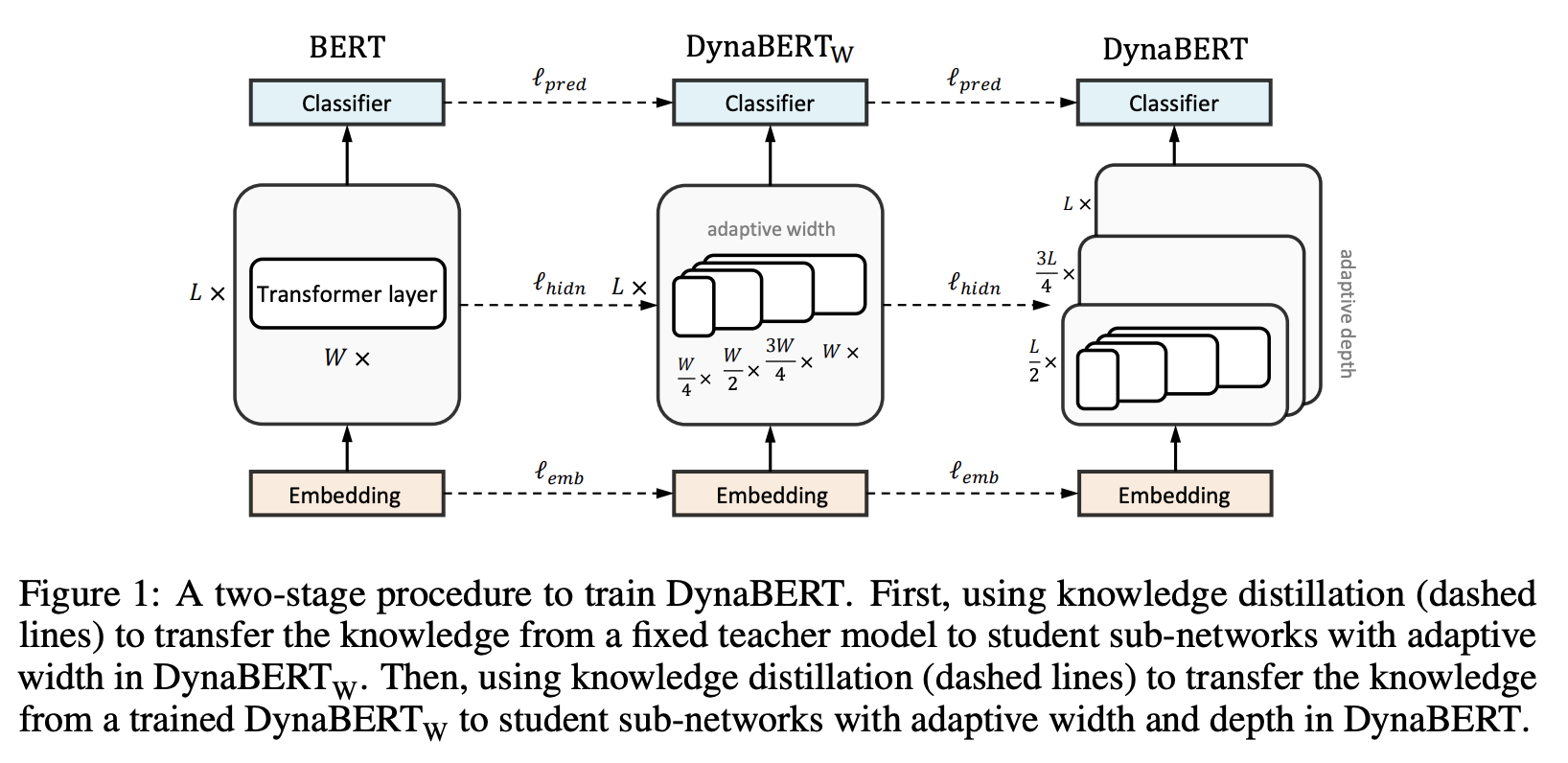
十一、DynaBERT
DynaBERT 是 BERT 的变体,可以通过选择自适应宽度和深度来灵活调整大小和延迟。 DynaBERT 的训练过程包括首先训练宽度自适应 BERT,然后通过将知识从全尺寸模型提炼到小型子网络来允许自适应宽度和深度。 网络重新布线还用于保持更多子网络共享更重要的注意力头和神经元。
使用两阶段程序来训练 DynaBERT。 首先,使用知识蒸馏(虚线)将知识从固定的教师模型转移到 DynaBERTW 中具有自适应宽度的学生子网络。 然后,使用知识蒸馏(虚线)将知识从训练有素的 DynaBERTW 转移到 DynaBERT 中具有自适应宽度和深度的学生子网络。
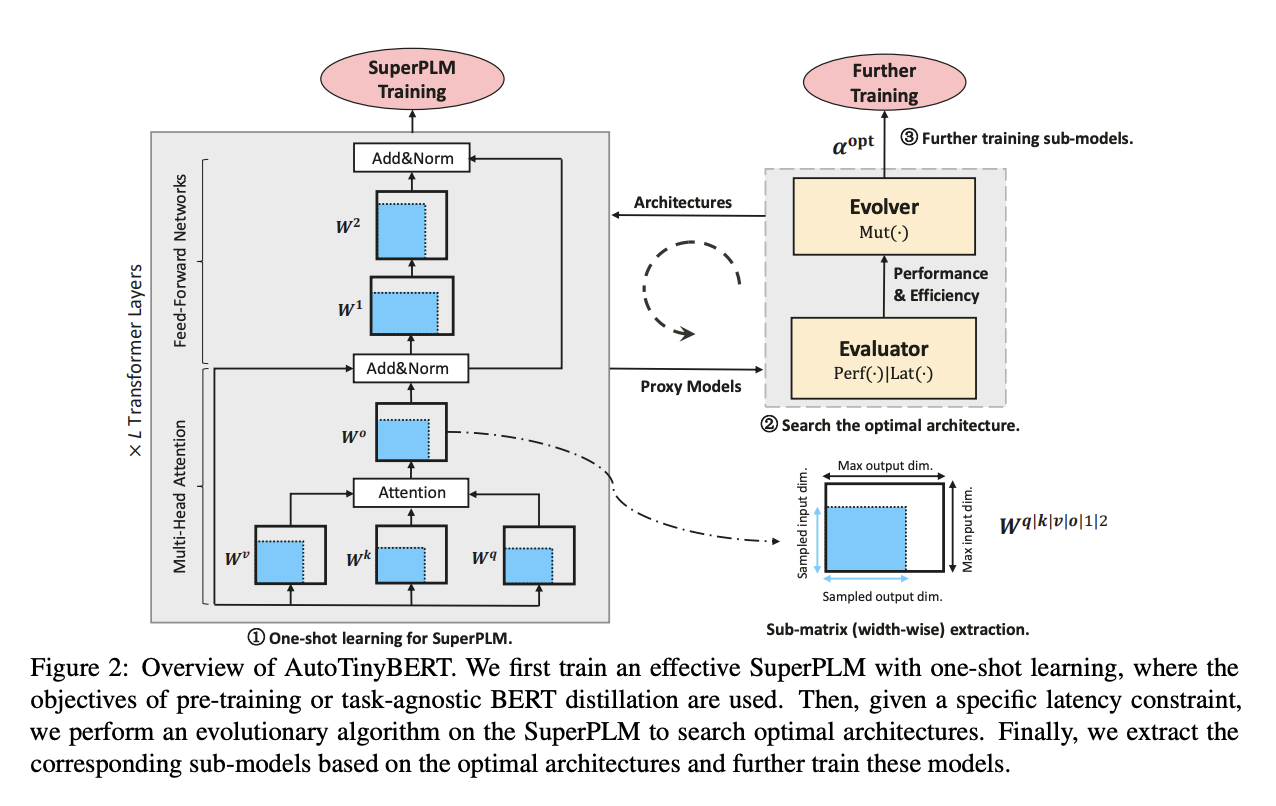
十二、AutoTinyBERT
AutoTinyBERT 是通过神经架构搜索发现的高效 BERT 变体。 具体来说,一次性学习用于获得大型超级预训练语言模型(SuperPLM),其中使用预训练或任务无关的 BERT 蒸馏的目标。 然后,在给定特定延迟约束的情况下,在 SuperPLM 上运行进化算法来搜索最佳架构。 最后,我们根据最优架构提取相应的子模型并进一步训练这些模型。