文章目录
一、Multi-Heads of Mixed Attention
混合注意力的多头结合了自我注意力和交叉注意力,鼓励对各种注意力特征中捕获的实体之间的交互进行高级学习。 它由多个注意力头构建,每个注意力头都可以实现自我注意力或交叉注意力。 自注意力是指关键特征和查询特征相同或来自相同的领域特征。 交叉注意力是指关键特征和查询特征是由不同的特征生成的。 MHMA 建模允许模型识别不同域的特征之间的关系。 这在涉及关系建模的任务中非常有用,例如人与物体交互、工具与组织交互、人机交互、人机界面等。
二、RealFormer
RealFormer 是一种基于剩余注意力思想的 Transformer。 它将跳跃边缘添加到主干 Transformer 中以创建多个直接路径,每个路径对应一种类型的注意力模块。 它不添加参数或超参数。 具体来说,RealFormer 使用 Post-LN 风格的 Transformer 作为主干,并添加跳边来连接相邻层中的多头注意力模块。

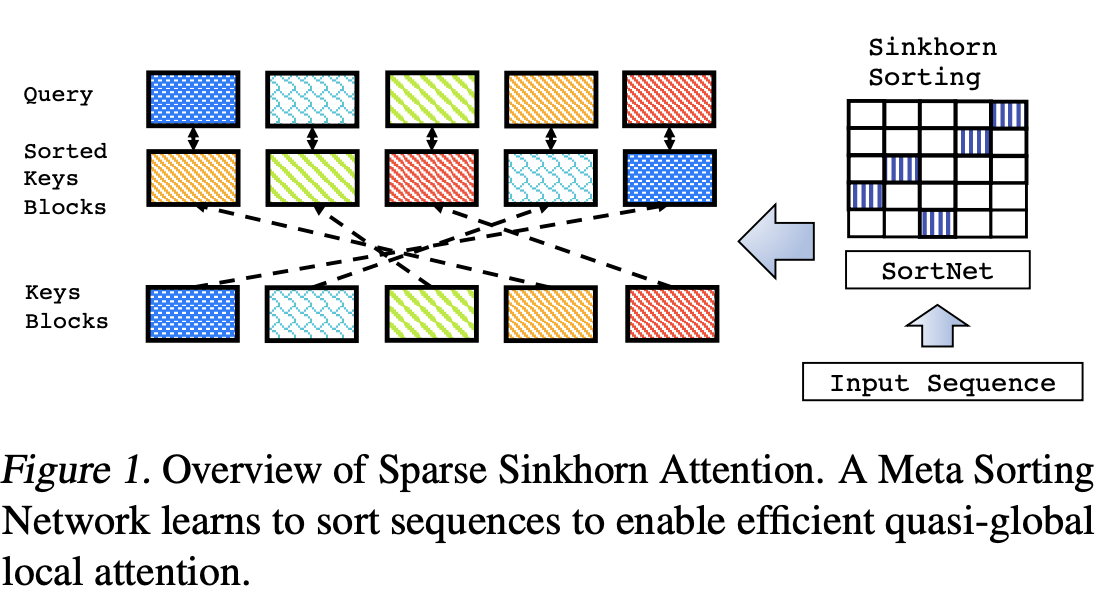
三、Sinkhorn Transformer
Sinkhorn Transformer 是一种使用稀疏 Sinkhorn Attention 作为构建块的变压器。 该组件是密集全连接注意力(以及局部注意力和稀疏注意力替代方案)的插件替代品,并允许降低内存复杂性和稀疏注意力。
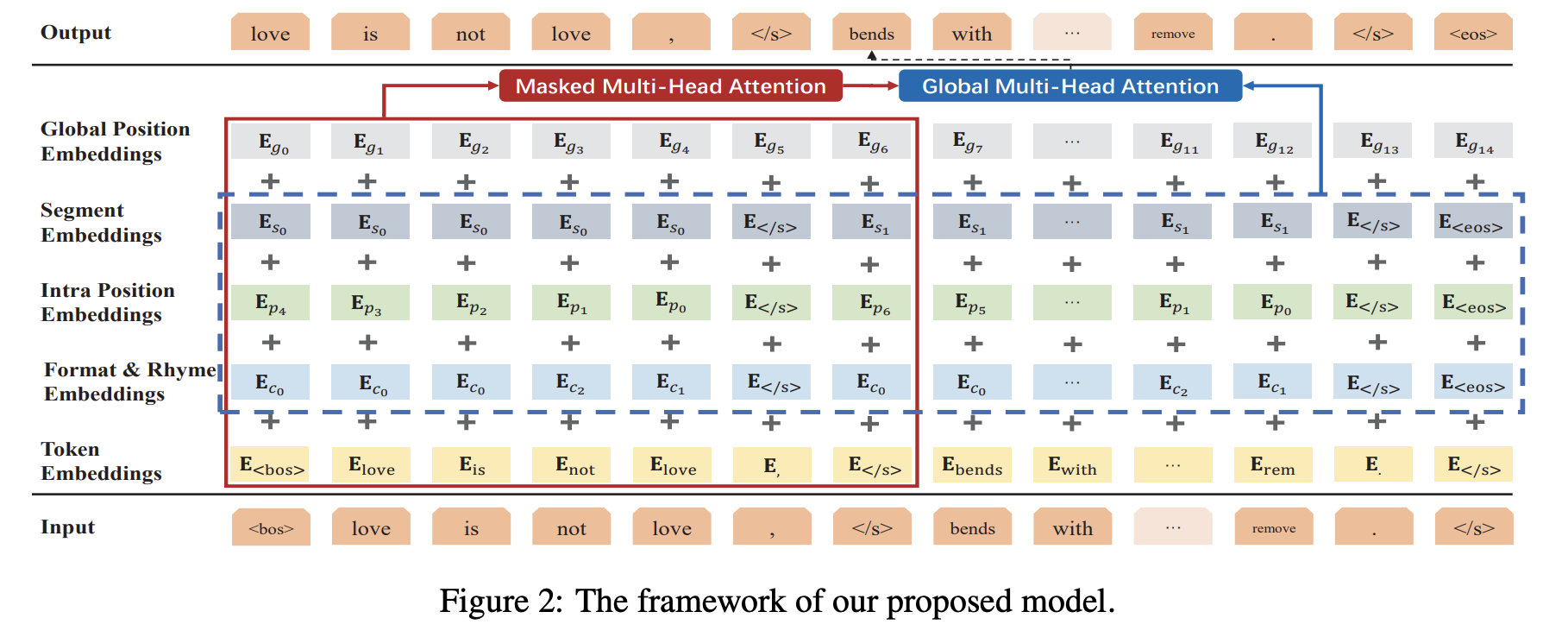
四、SongNet
SongNet 是一种基于 Transformer 的自回归语言模型,用于严格格式文本检测。 符号集经过专门设计,可提高建模性能,尤其是在格式、韵律和句子完整性方面。 改进了注意力机制,以促使模型捕获有关格式的一些未来信息。 设计了预训练和微调框架以进一步提高生成质量。
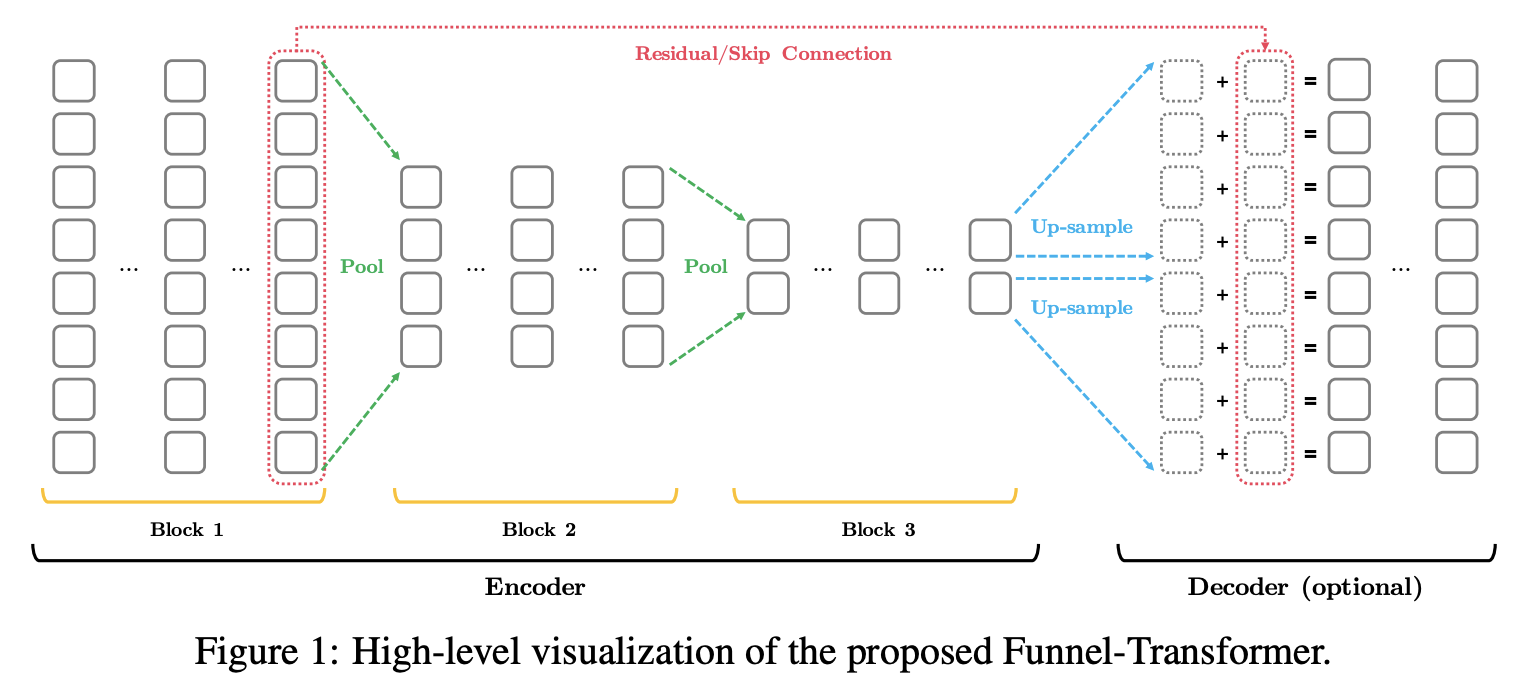
五、Funnel Transformer
漏斗变压器是变压器的一种,它逐渐将隐藏状态序列压缩为更短的序列,从而降低计算成本。 通过将长度减少所节省的 FLOP 重新投入到构建更深或更宽的模型中,模型容量进一步提高。 此外,为了根据常见预训练目标的要求执行令牌级预测,Funnel-transformer 能够通过解码器从简化的隐藏序列中恢复每个令牌的深度表示。
所提出的模型保持由残差连接和层归一化包裹的交错 S-Attn 和 P-FFN 子模块的相同整体骨架。 但不同的是,为了实现表示压缩和计算减少,该模型采用了一个编码器,随着层的加深,该编码器逐渐减少隐藏状态的序列长度。 此外,对于涉及每个令牌预测(例如预训练)的任务,使用简单的解码器从压缩编码器输出中重建令牌级表示的完整序列。 压缩是通过池化操作实现的
六、Transformer Decoder
Transformer-Decoder 是针对长序列的 Transformer-Encoder-Decoder 的修改,它删除了编码器模块,将输入和输出序列组合成单个“句子”,并作为标准语言模型进行训练。 它用于 GPT 及其后续版本。
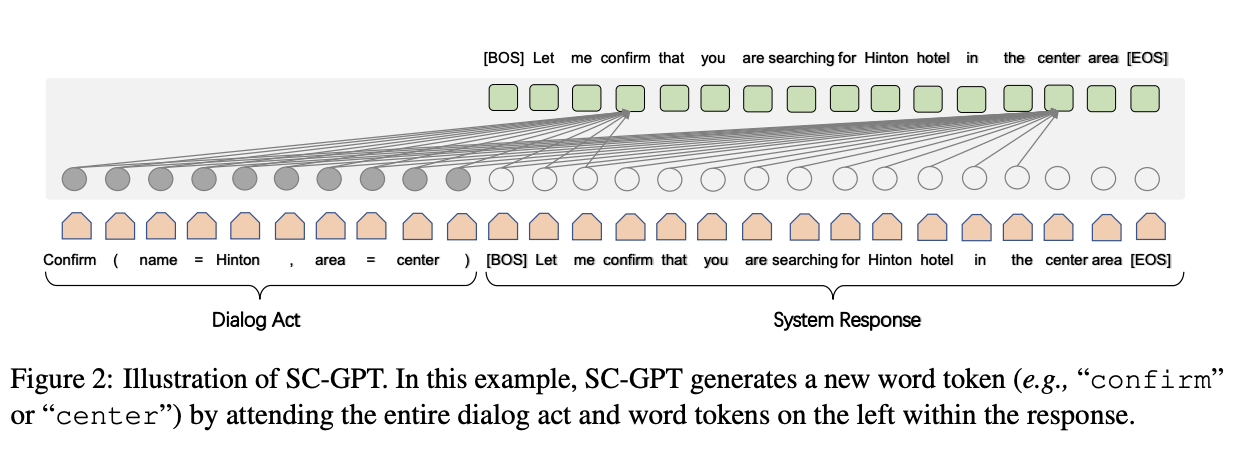
七、SC-GPT
SC-GPT 是一个多层 Transformer 神经语言模型,分三个步骤进行训练:(i)在纯文本上进行预训练,类似于 GPT-2; (ii) 对大量对话行为标记话语语料库进行持续预训练,获得可控生成的能力; (iii) 使用非常有限数量的域标签针对目标域进行微调。 与 GPT-2 不同,SC-GPT 生成以给定语义形式为条件的语义控制响应,类似于 SC-LSTM,但需要更少的域标签来泛化到新域。 它在大量带注释的 NLG 语料库上进行预训练,以获得可控的生成能力,并仅使用少数特定领域的标签进行微调以适应新领域。
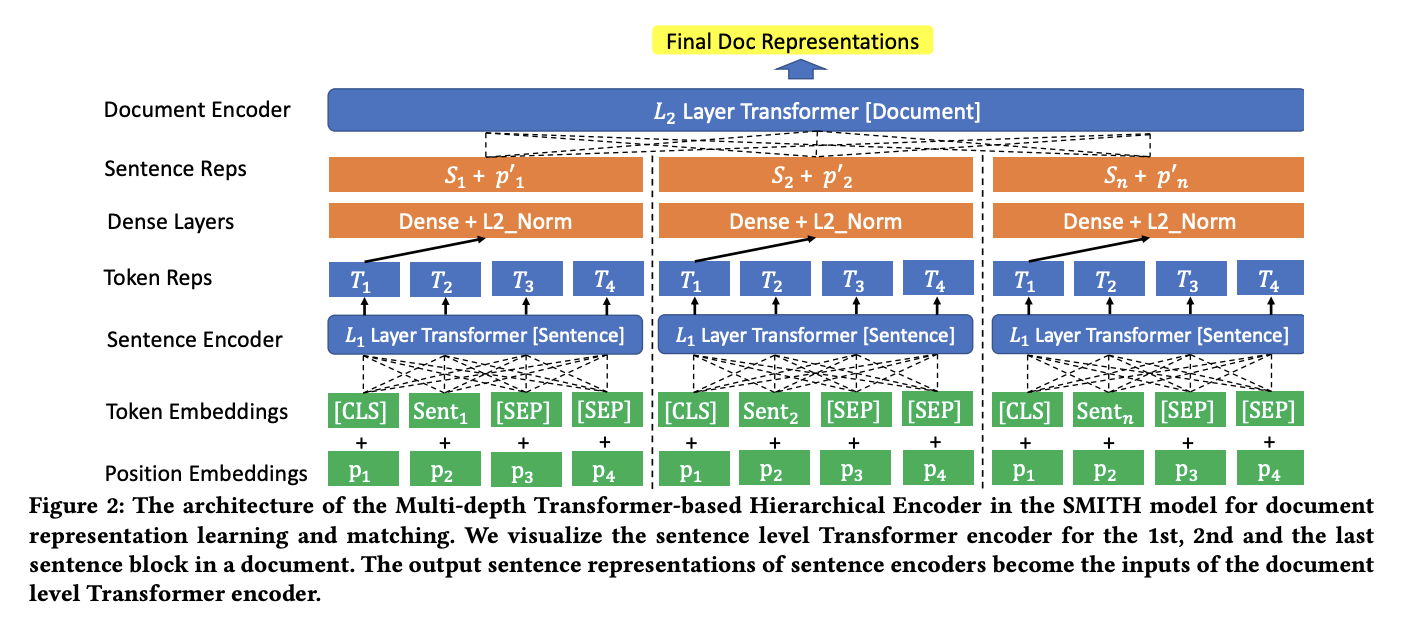
七、Siamese Multi-depth Transformer-based Hierarchical Encoder(SMITH)
SMITH(即 Siamese Multi-depth Transformer-based Hierarchical Encoder)是一种基于 Transformer 的文档表示学习和匹配模型。 它包含多种设计选择,以使自注意力模型适应长文本输入。 对于模型预训练,除了 BERT 中使用的原始掩码词语言模型任务之外,还使用了掩码句子块语言建模任务,以捕获文档内的句子块关系。 给定一系列句子块表示,文档级 Transformer 学习每个句子块的上下文表示和最终文档表示。
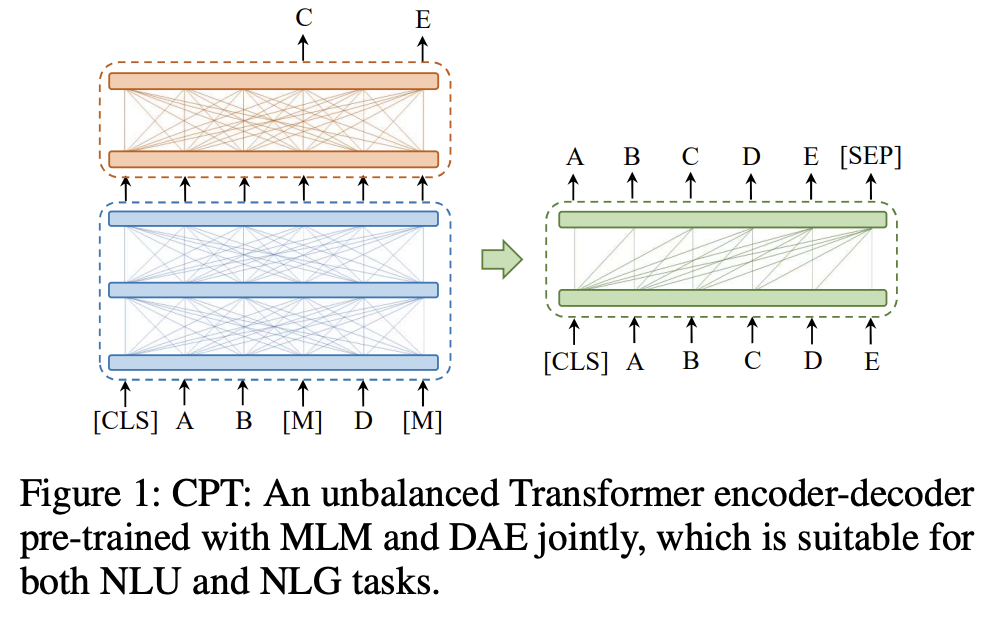
八、Chinese Pre-trained Unbalanced Transformer
CPT,即Chinese Pre-trained Unbalanced Transformer,是用于中文自然语言理解(NLU)和自然语言生成(NLG)任务的预训练不平衡Transformer。 CPT由三部分组成:共享编码器、理解解码器和生成解码器。 具有共享编码器的两个特定解码器分别通过掩码语言建模(MLM)和去噪自动编码(DAE)任务进行预训练。 通过部分共享的架构和多任务预训练,CPT 可以(1)使用两个解码器学习 NLU 或 NLG 任务的特定知识,(2)灵活微调,充分发挥模型的潜力。 具有共享编码器的两个特定解码器分别通过掩码语言建模(MLM)和去噪自动编码(DAE)任务进行预训练。 通过部分共享的架构和多任务预训练,CPT 可以(1)使用两个解码器学习 NLU 或 NLG 任务的特定知识,(2)灵活微调,充分发挥模型的潜力。
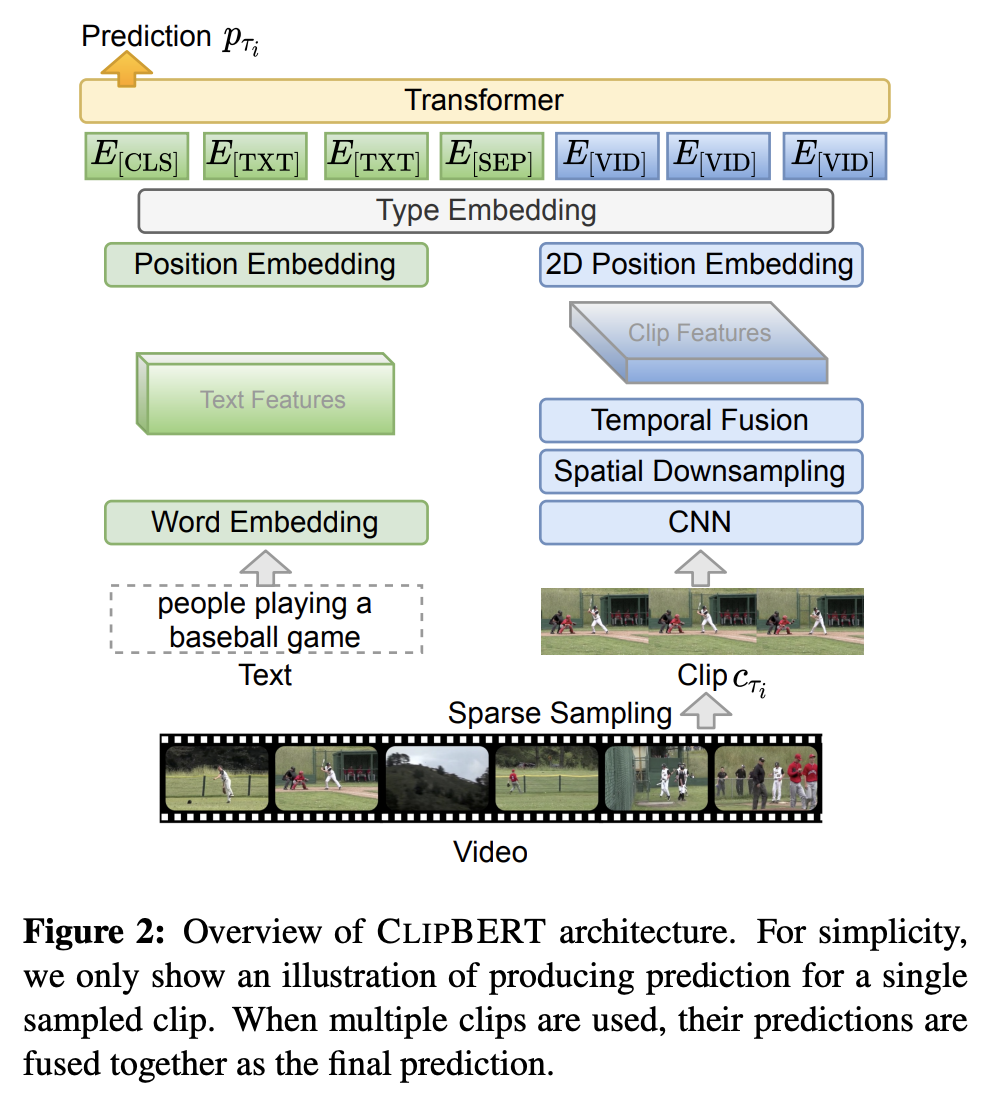
九、ClipBERT
ClipBERT 是一个用于视频和语言任务的端到端学习的框架,它采用稀疏采样,其中每个训练步骤仅使用视频中的一个或几个稀疏采样的短片。 ClipBERT 与之前的工作有两个不同之处。
首先,与密集提取视频特征(大多数现有方法采用的)相比,CLIPBERT 在每个训练步骤中仅从完整视频中稀疏地采样一个或几个短剪辑。 假设是稀疏剪辑的视觉特征已经捕获了视频中的关键视觉和语义信息,因为连续剪辑通常包含来自连续场景的相似语义。 因此,几个剪辑就足以进行训练,而不是使用完整的视频。 然后,聚合来自多个密集采样片段的预测,以在推理过程中获得最终的视频级预测,这对计算量要求较低。
第二个区别方面涉及模型权重的初始化(即通过预训练进行转移)。 作者使用 2D 架构(例如 ResNet-50)而不是 3D 特征作为视频编码的视觉主干,使他们能够利用图像文本预训练的强大功能来理解视频文本,以及低内存成本和运行时间的优势 效率。
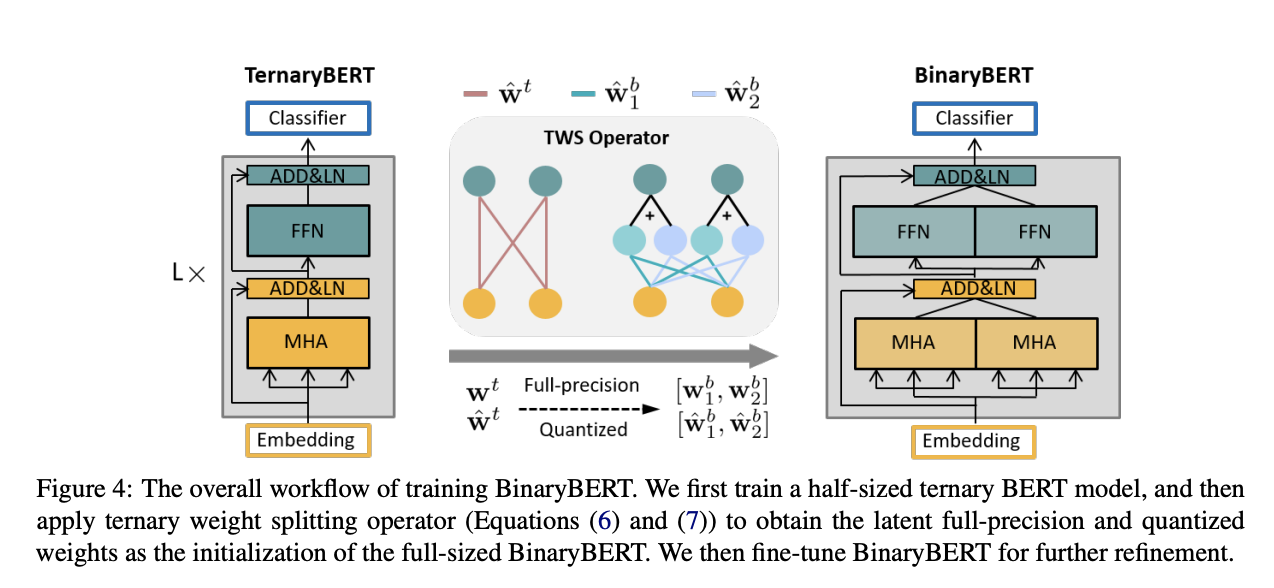
十、BinaryBERT
BinaryBERT 是 BERT 的变体,以权重二值化的形式应用量化。 具体来说,提出了三元权重分割,通过从一半大小的三元网络进行等效分割来初始化 BinaryBERT。 为了获得 BinaryBERT,我们首先训练半尺寸的三元 BERT 模型,然后应用三元权重分割算子来获得潜在的全精度和量化权重,作为全尺寸 BinaryBERT 的初始化。 然后,我们对 BinaryBERT 进行微调以进一步细化。