文章目录
一、TernaryBERT
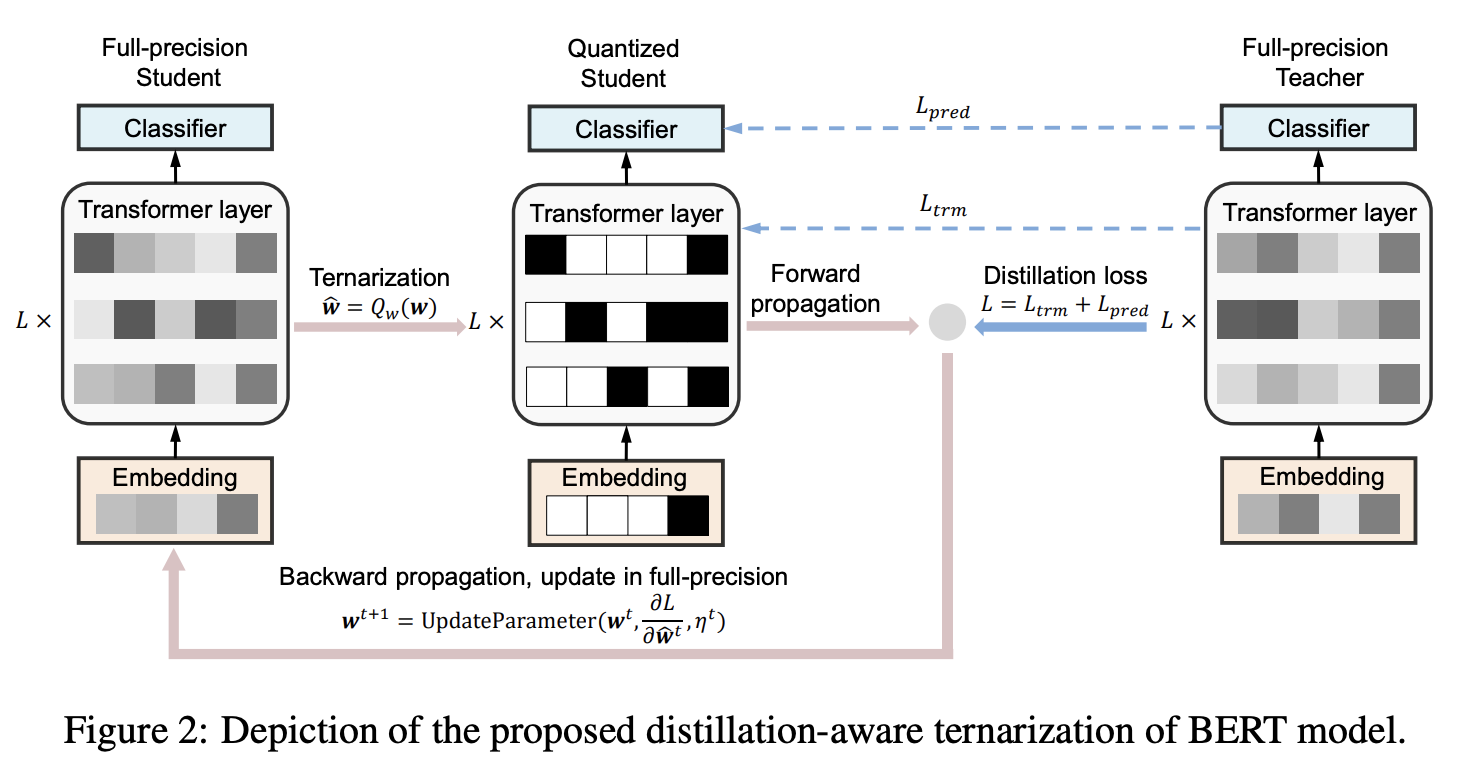
TernaryBERT 是一个基于 Transformer 的模型,它将预训练的 BERT 模型的权重三元化为-1、0、1,在 Transformer 层中具有不同的词嵌入粒度和权重。 它不是直接使用知识蒸馏来压缩模型,而是用于提高与教师模型大小相同的三元化学生模型的性能。 通过这种方式,我们将知识从高精度的教师模型迁移到容量较小的三元化学生模型。
二、Fastformer
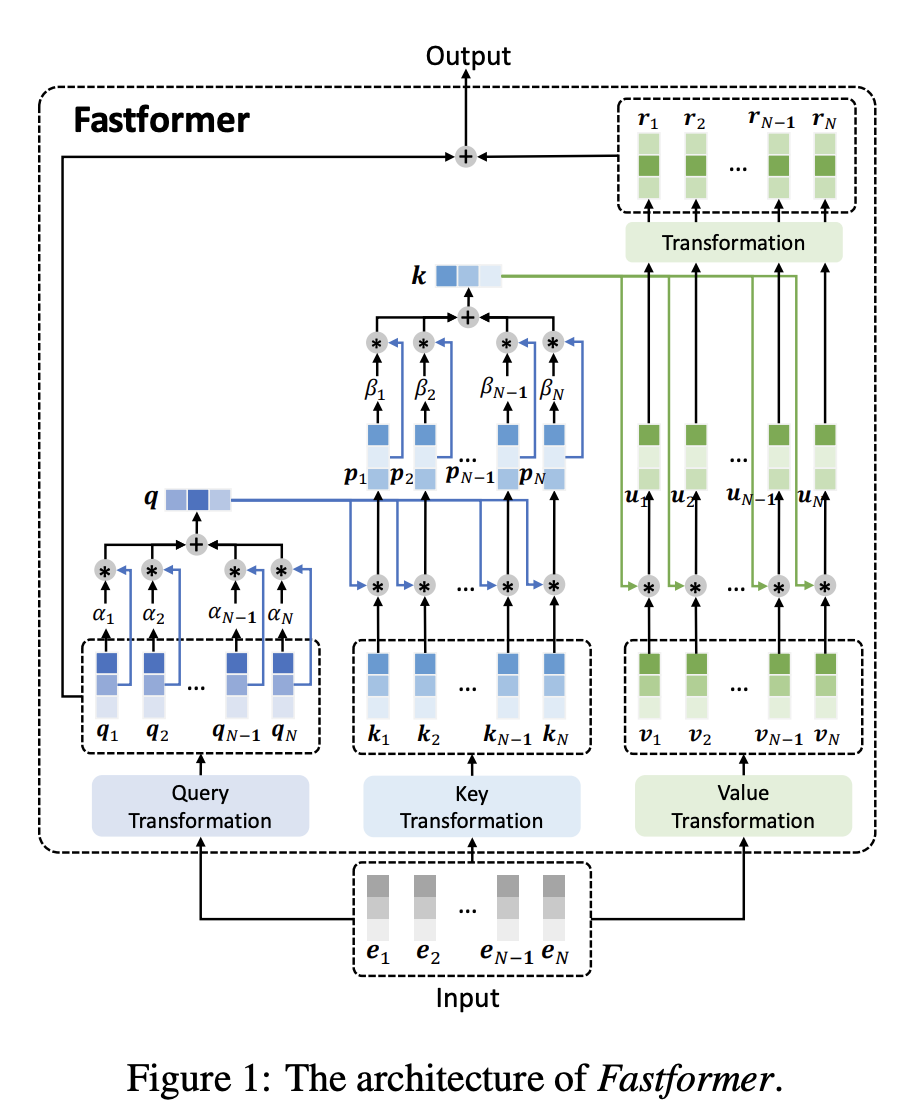
Fastformer 是 Transformer 的一种,它使用附加注意力作为构建块。 不是对令牌之间的成对交互进行建模,而是使用附加注意力来对全局上下文进行建模,然后每个令牌表示根据其与全局上下文表示的交互进行进一步转换。
三、Parallel Layers
并行层 - 我们在每个 Transformer 块中使用“并行”公式(Wang 和 Komatsuzaki,2021),而不是标准的“串行”公式。 具体来说,标准公式可以写为:
y = x + MLP(LayerNorm(x + Attention(LayerNorm(x)))
而并行公式可以写为:
y = x + MLP(LayerNorm(x)) + Attention(LayerNorm(x))
由于 MLP 和 Attention 输入矩阵乘法可以融合,并行公式使大规模训练速度提高了大约 15%。 烧蚀实验显示,在 8B 尺度下质量略有下降,但在 62B 尺度下没有质量下降,因此我们推断并行层的效果在 540B 尺度上应该是质量中性的。
四、DeLighT
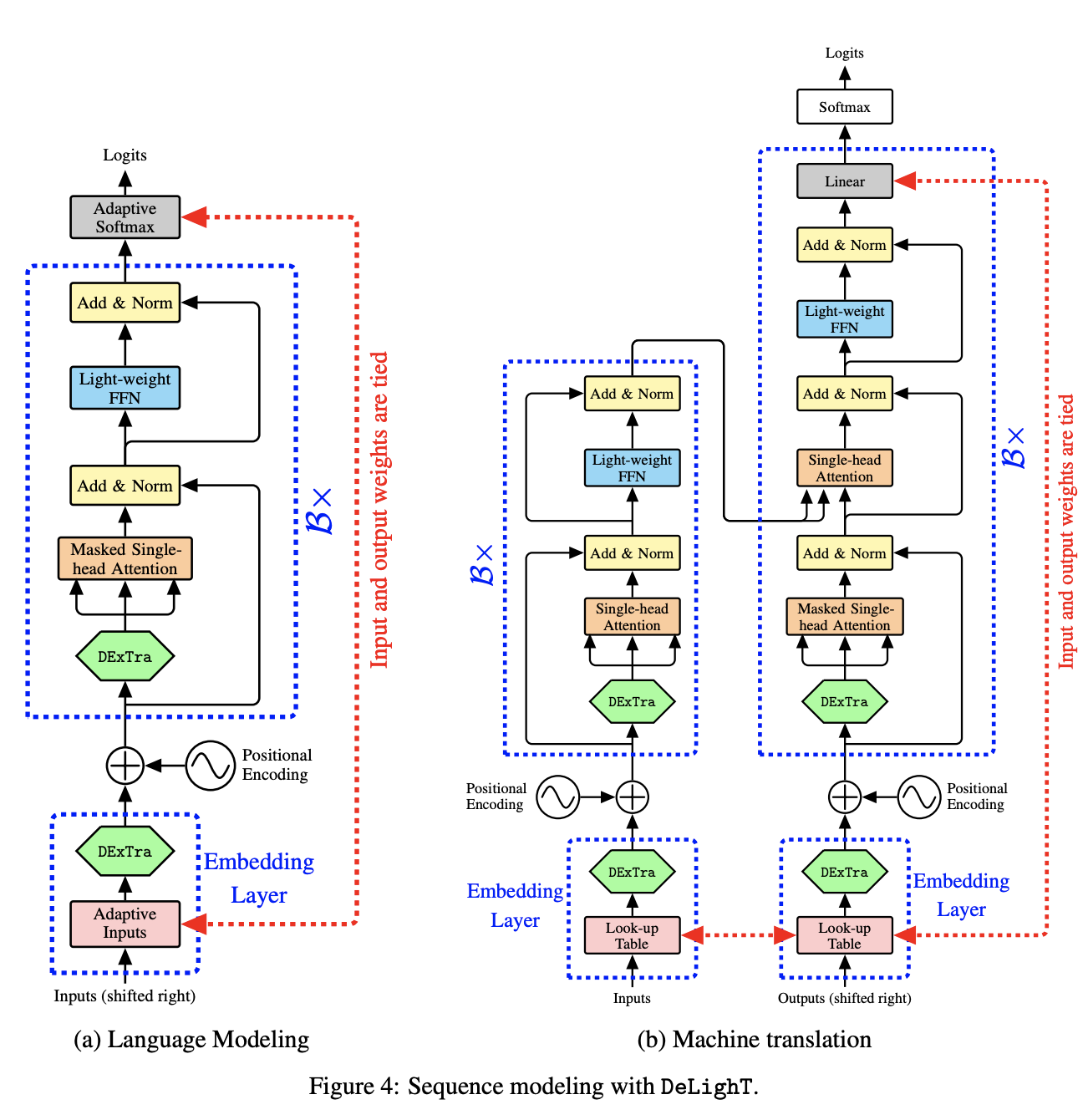
DeLiGHT 是一种 Transformer 架构,它通过以下方式实现参数效率改进:(1) 在每个 Transformer 块内使用 DExTra(一种深度轻量级转换),允许使用单头注意力和瓶颈 FFN 层,以及 (2) 使用块跨块 明智的缩放,允许在输入附近使用更浅和更窄的 DeLighT 块,在输出附近使用更宽和更深的 DeLighT 块。
五、PAR Transformer
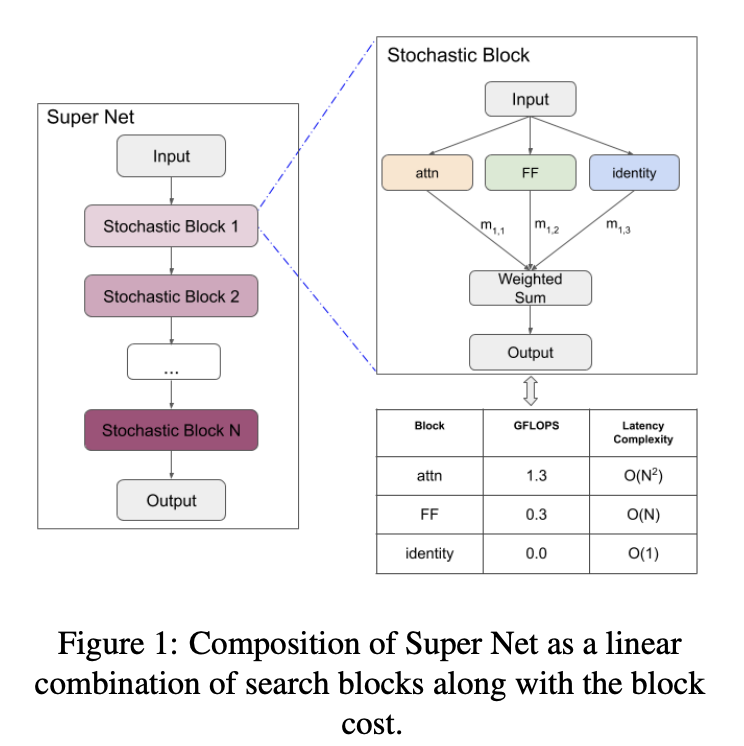
PAR Transformer 是一种 Transformer 模型,它使用的自注意力块减少了 63%,并用前馈块取代,同时保留了测试精度。 它基于 Transformer-XL 架构,并使用神经架构搜索来查找 Transformer 架构中的有效块模式。
六、ConvBERT
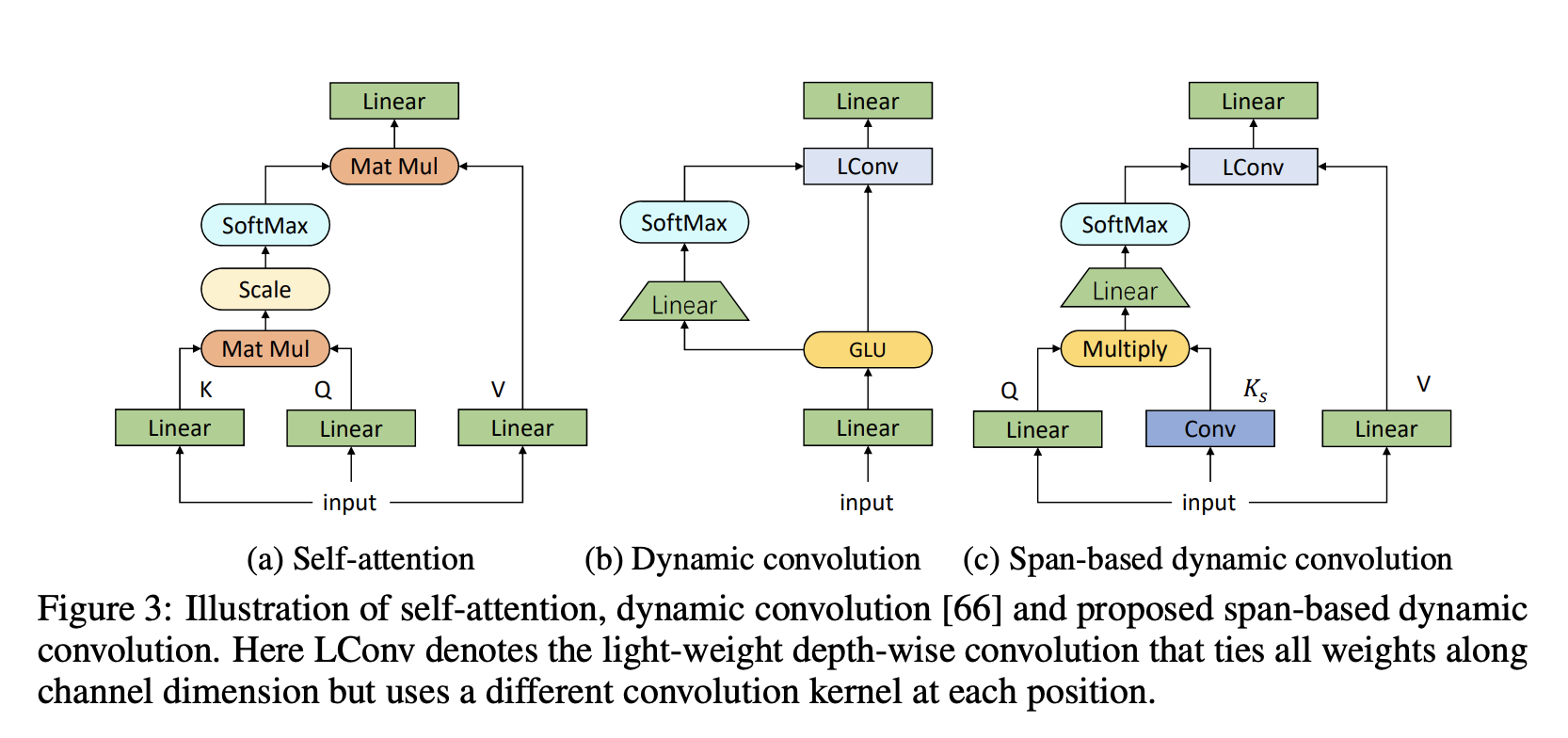
ConvBERT 是 BERT 架构的修改版,它使用基于跨度的动态卷积来代替自注意力头来直接对局部依赖关系进行建模。 具体来说,一个新的混合注意力模块取代了 BERT 中的自注意力模块,它利用卷积的优势来更好地捕获局部依赖性。 此外,还使用了一种新的基于跨度的动态卷积运算,以利用多个输入标记来动态生成卷积核。 最后,ConvBERT 还融入了一些新的模型设计,包括瓶颈注意力和前馈模块的分组线性算子(减少参数数量)。
七、Enhanced Seq2Seq Autoencoder via Contrastive Learning(ESACL)
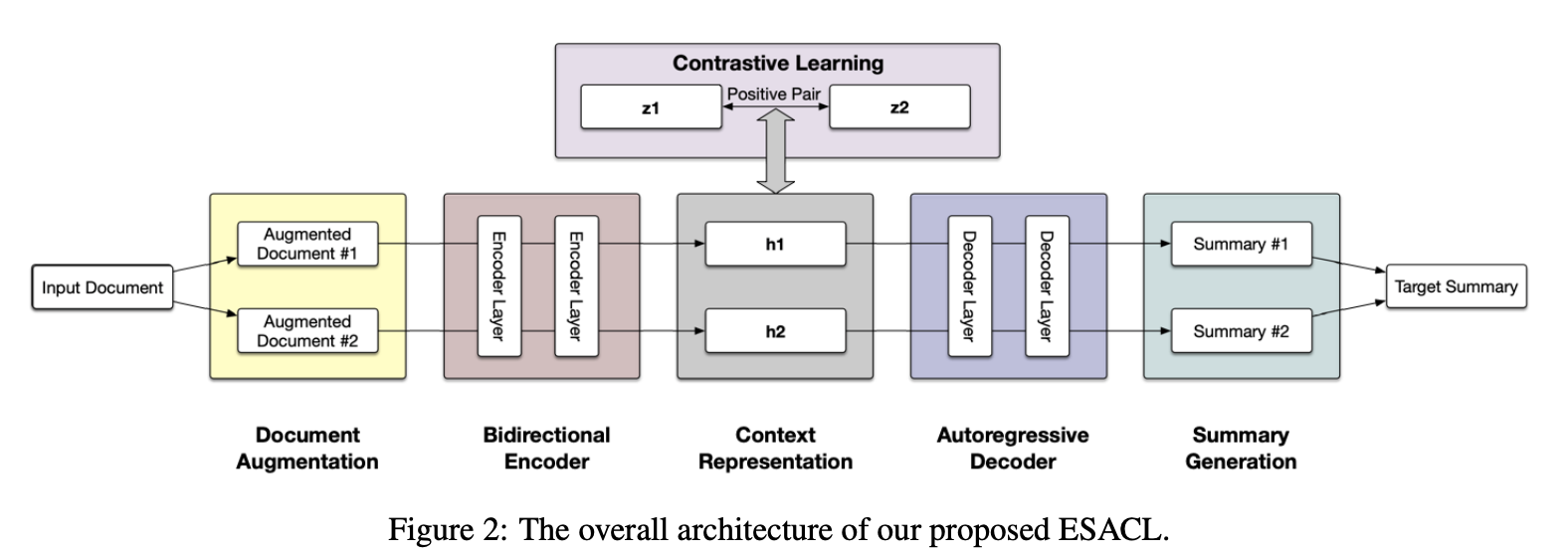
ESACL(通过对比学习增强型 Seq2Seq 自动编码器)是一种通过对比学习进行去噪的序列到序列 (seq2seq) 自动编码器,用于抽象文本摘要。 该模型采用标准的基于 Transformer 的架构,具有多层双向编码器和自回归解码器。 为了增强其去噪能力,将自监督对比学习与各种句子级文档增强相结合。
八、PermuteFormer
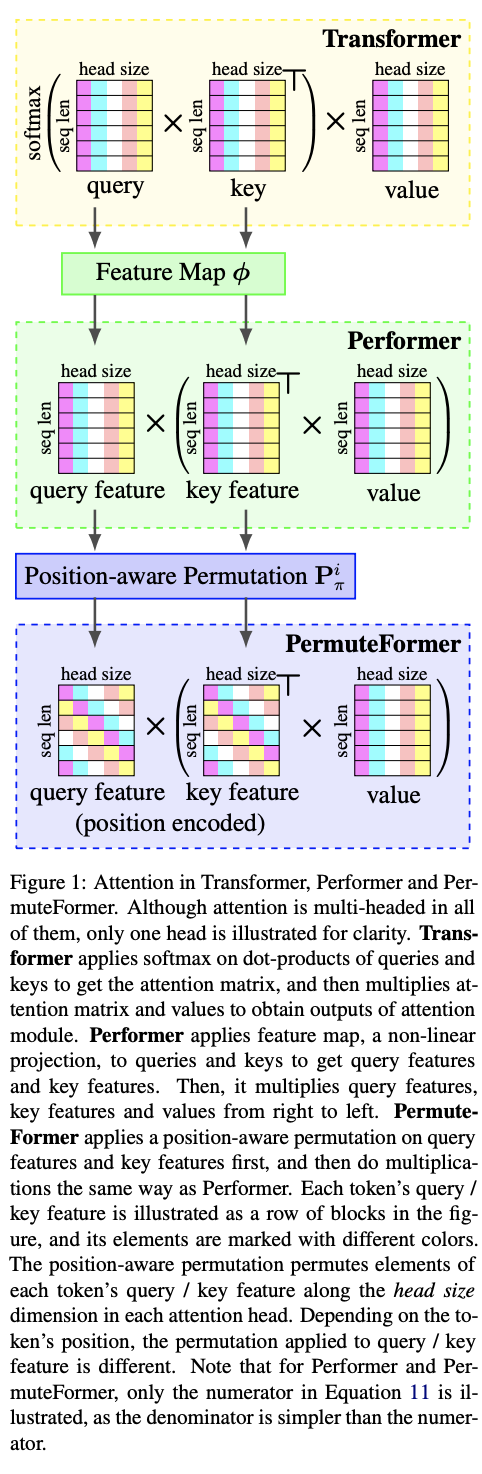
PermuteFormer 是一种基于 Performer 的模型,具有相对位置编码,可在长序列上线性缩放。 PermuteFormer 对查询和键应用位置相关的变换,将位置信息编码到注意模块中。 这种转换是经过精心设计的,以便自注意力的最终输出不受令牌绝对位置的影响。
每个token的查询/关键特征在图中被表示为一行块,并且其元素用不同的颜色标记。 位置感知排列沿着每个注意力头中的头大小维度排列每个标记的查询/关键特征的元素。 根据令牌的位置,应用于查询/关键特征的排列是不同的。
九、NormFormer
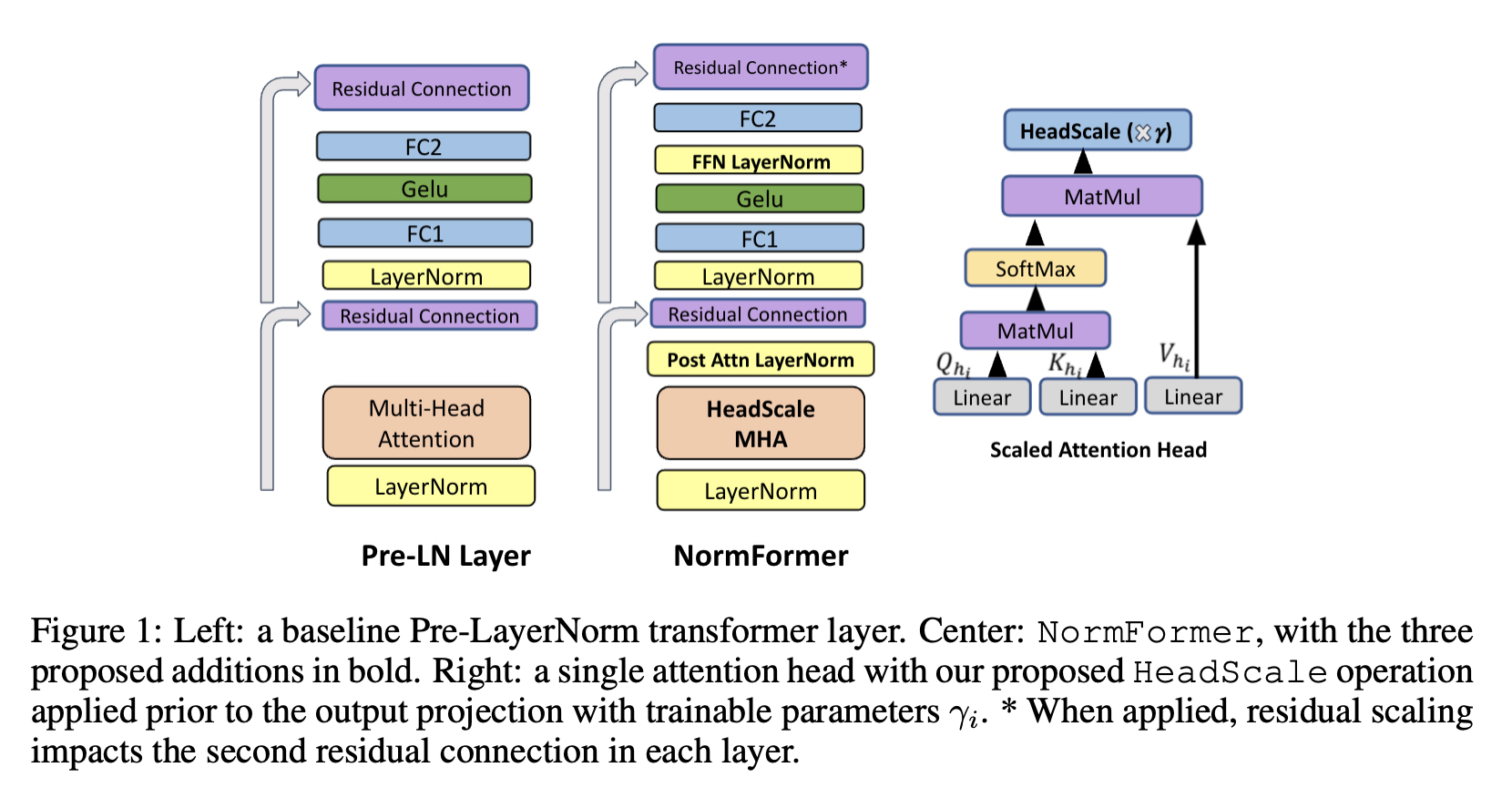
NormFormer 是一种 Pre-LN 转换器,它为每一层添加了三个归一化操作:自注意力之后的层范数、自注意力输出的头向缩放以及第一个全连接层之后的层范数。 这些修改引入了少量额外的可学习参数,这些参数为每一层提供了一种经济高效的方法来改变其特征的大小,从而改变后续组件的梯度大小。
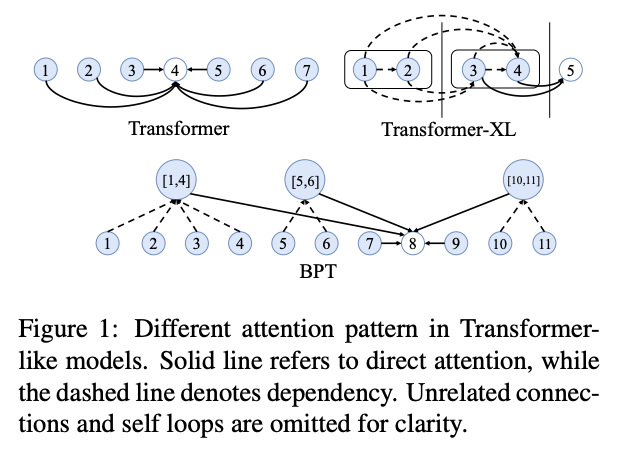
十、BP-Transformer
BP-Transformer (BPT) 是 Transformer 的一种,其动机是需要在自注意力的能力和计算复杂性之间找到更好的平衡。 该架构通过二进制划分(BP)将输入序列划分为不同的多尺度范围。 它结合了随着相对距离的增加而关注上下文信息从细粒度到粗粒度的归纳偏差。 上下文信息越远,其表示越粗糙。 BPT可以看作是图神经网络,其节点是多尺度跨度。 令牌节点可以参与较近上下文的较小规模跨度和较远距离上下文的较大规模跨度。 节点的表示通过图自注意力进行更新。
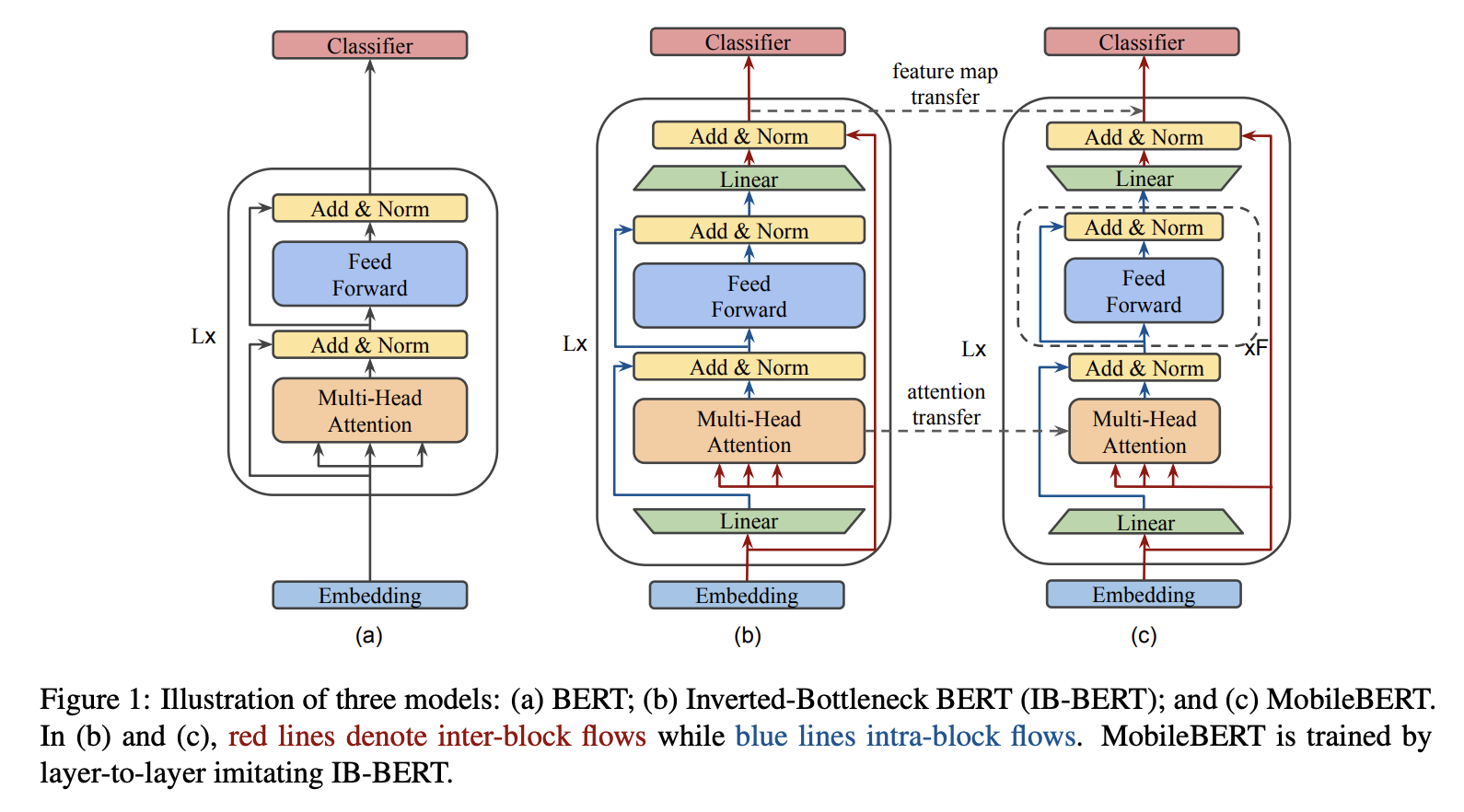
十一、Inverted Bottleneck BERT(IB-BERT)
IB-BERT,即 Inverted Bottleneck BERT,是使用倒瓶颈结构的 BERT 变体。 它用作教师网络来训练 MobileBERT 模型。
十二、MacBERT
MacBERT 是一个基于 Transformer 的中文 NLP 模型,它以多种方式改变了 RoBERTa,包括修改后的掩蔽策略。 MacBERT 没有使用在微调阶段从未出现的 [MASK] 标记进行屏蔽,而是使用其相似的单词来屏蔽该单词。 具体来说,MacBERT 与 BERT 共享相同的预训练任务,但有一些修改。 对于MLM任务,进行以下修改:
使用全字掩码以及 Ngram 掩码策略来选择掩码候选标记,字级一元到 4 元的比例为 40%、30%、20%、10%。
与使用[MASK]标记进行掩码不同,该标记在微调阶段中从未出现过,而是使用类似的单词来达到掩码目的。 使用基于word2vec相似度计算的Synonyms工具包获得相似词。 如果选择一个 N-gram 来屏蔽,我们将单独找到相似的单词。 在极少数情况下,当没有相似的单词时,我们会降级使用随机单词替换。
15%的输入单词用于掩码,其中80%将替换为相似单词,10%替换为随机单词,其余10%保留原始单词。
