注:此系列文章里的部分算法和深度学习笔记系列里的内容有重合的地方,深度学习笔记里是看教学视频做的笔记,此处文章是看《机器学习实战》这本书所做的笔记,虽然算法相同,但示例代码有所不同,多敲一遍没有坏处,哈哈。(里面用到的数据集、代码可以到网上搜索,很容易找到。)。Python版本3.6
机器学习十大算法系列文章:
机器学习实战笔记1—k-近邻算法
机器学习实战笔记2—决策树
机器学习实战笔记3—朴素贝叶斯
机器学习实战笔记4—Logistic回归
机器学习实战笔记5—支持向量机
机器学习实战笔记6—AdaBoost
机器学习实战笔记7—K-Means
此系列源码在我的GitHub里:https://github.com/yeyujujishou19/Machine-Learning-In-Action-Codes
一,算法原理:
1)贝叶斯公式:
a)正向思维:
什么是正向思维?有一个很典型的例子就是,有一个黑箱子,我们已经知道里面有N个白球和M个黑球,那么我们就能知道闭着眼睛随机抽出来的球的概率。正向思维就是我们只有知道了所有可能发生的情况,才能推断出每个情况发生的概率。
b)倒向思维:
倒向思维是,如果我们事先并不知道黑箱里面黑白球的比例,而是闭着眼睛摸出一个或好几个球,观察这些取出来的球的颜色之后,就此对黑箱里面的黑白球的比例进行推测,但是推测不出箱子里面球的数量。通俗地讲,就是通过一些已知的概率可以求一些未知的概率。贝叶斯公式就是用倒向思维来求条件概率的。
c)条件概率:
先看条件概率的符号表示:P(B|A),意思是在事件A发生的条件下,事件B发生的概率。刚才说贝叶斯公式是求条件概率的,那是时候要亮出贝叶斯公式了:
P(B|A) = P(AB) / P(A)
我们先来理解 P(B|A) 究竟是个什么鬼,P(B|A) 是在事件A发生的条件下,事件B发生的概率。有人还是很难理解,我们换个说法,P(B|A) 在公式里面的意思是 P(AB) 占 P(A) 的比重。来看下面的文氏图来辅助理解 P(AB) 占 P(A) 的比重是什么意思。
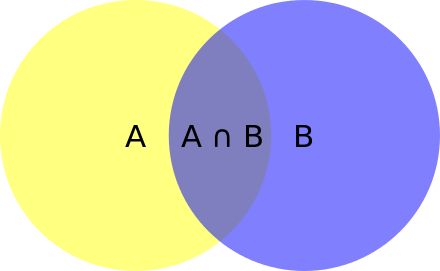
d)全概率:
公式表示若事件A1,A2,…,An构成一个完备事件组且都有正概率,则对任意一个事件B都有公式成立。
举例:以吃鸡游戏玩家小明同学玩了100局游戏为例(其中涉及“开黑”术语是和朋友一起玩游戏的意思)。
玩家小明胜利情况
| 玩家 | 总游戏局数 | 总胜利局数 | 开黑局数 | 开黑且胜利的局数 |
|---|---|---|---|---|
| 小明 | 100 | 80 | 34 | 24 |
正向思维:
设A事件为玩家胜利: P(A) = 80/100 = 0.8
设B事件为玩家开黑: P(B) = 34/100 = 0.34
设AB事件为玩家开黑且胜利: P(AB) = 24/100 = 0.24
条件概率:
设C事件为如果玩家胜利,此胜利局为开黑局: P(C) = P(B|A) = P(AB) / P(A) = 0.24/0.8 = 0.3
设D事件为如果玩家开黑,此开黑局为胜利局: P(D) = P(A|B) = P(AB) / P(B) = 0.24/0.34 = 0.7
倒向思维:
玩家小明胜利情况
| 玩家 | 总胜率 | 胜利局中为开黑局的可能性 | 失败局中为开黑局的可能性 |
|---|---|---|---|
| 小明 | 0.8 | 0.3 | 0.5 |
我们要做的是,根据表格中的已知的概率,来求玩家在开黑局中胜利的概率。
设A事件为玩家胜利:
P(A) = 0.8
P(~A) = 1 - P(A) = 1-0.8 = 0.2
设B事件为玩家开黑,根据已知条件概率有
胜利局中为开黑局的可能性: P(B|A) = 0.3
失败局中为开黑局的可能性: P(B|~A) = 0.5
根据全概率公式求玩家玩游戏会开黑的概率
P(B) = P(B|A) * P(A) + P(B|~A) * P(~A)
= 0.3*0.8 + 0.5*0.2
= 0.34
设C事件为玩家在开黑局中取得胜利
(计算过程中将贝叶斯公式展开,其中分母由全概率公式求得)
P(C) = P(A|B) = P(AB) / P(B)
= P(B|A) * P(A) / ( P(B|A) * P(A) + P(B|~A) * P(~A) )
= 0.71
2)朴素贝叶斯:
朴素贝叶斯算法,朴素:特征条件独立;贝叶斯:基于贝叶斯定理。朴素贝叶斯中的朴素一词的来源就是假设各特征之间相互独立。这一假设使得朴素贝叶斯算法变得简单,但有时会牺牲一定的分类准确率。
那么既然是朴素贝叶斯分类算法,它的核心算法又是什么呢?是下面这个贝叶斯公式:
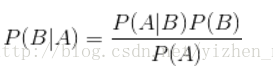
换个表达形式就会明朗很多,如下:
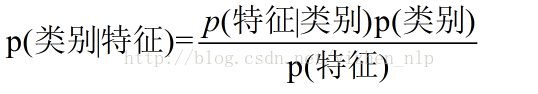
我们最终求的p(类别|特征)即可!就相当于完成了我们的任务。
举例:病人分类的例子,某个医院早上收了六个门诊病人,如下表:
| 症状 | 职业 | 疾病 |
| 打喷嚏 | 护士 | 感冒 |
| 打喷嚏 | 农夫 | 过敏 |
| 头痛 | 建筑工人 | 脑震荡 |
| 头痛 | 建筑工人 | 感冒 |
| 打喷嚏 | 教师 | 感冒 |
| 头痛 | 教师 | 脑震荡 |
现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大? 根据贝叶斯定理:
P(A|B) = P(B|A) P(A) / P(B)可得:
P(感冒|打喷嚏x建筑工人) = P(打喷嚏x建筑工人|感冒) x P(感冒) / P(打喷嚏x建筑工人)假定”打喷嚏”和”建筑工人”这两个特征是独立的,因此,上面的等式就变成了:
P(感冒|打喷嚏x建筑工人) = P(打喷嚏|感冒) x P(建筑工人|感冒) x P(感冒) / P(打喷嚏) x P(建筑工人)这是可以计算的:
P(感冒|打喷嚏x建筑工人) = 0.66 x 0.33 x 0.5 / 0.5 x 0.33 = 0.66因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
二,算法的优缺点:
优点:
(1)在数据较少的情况下仍然有效,可以处理多类别问题。
(2)算法逻辑简单,易于实现(算法思路很简单,只要使用贝叶斯公式转化即可!)
(3)分类过程中时空开销小(假设特征相互独立,只会涉及到二维存储)
缺点:
(1)对于输入数据的准备方式较为敏感。
(2)朴素贝叶斯假设属性之间相互独立,这种假设在实际过程中往往是不成立的。在属性之间相关性越大,分类误差也就越大。
适用数据类型:标称型数据。
三,实例代码:使用Python进行文本分类
1)准备数据,从文本构建词向量
从文本转换成不重复的单词,再从单词转换成数字。
将单词分为侮辱性和非侮辱性的,侮辱性单词标记为1,非侮辱性的标记为0。
#加载数据集
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1代表侮辱性文字,0代表正常言论
return postingList,classVec
#创建一个包含在所有文档中出现的不重复词的列表
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空集,将词条列表输给set构造函数,set就会返回一个不重复词表
for document in dataSet:
vocabSet = vocabSet | set(document) #创建两个集合的并集,操作符
return list(vocabSet)
#vocabList 词汇表
#inputSet 某个文档
#函数输出是文档向量,向量的每一元素为1或0,分别表示词汇表中的单词在输入文档中是否出现
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList) #先创建一个和词汇表等长的向量,并将其元素都设置为0
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1 #如果词汇表中的单词在文档中,将相应位置置1
else: print ("the word: %s is not in my Vocabulary!" % word) #Vocabulary词汇
return returnVec
#测试
listOPosts,listClasses=loadDataSet() #加载数据
myVocablist=createVocabList(listOPosts) #创建词汇表
print(myVocablist) #打印词汇表
returnVec=setOfWords2Vec(myVocablist,listOPosts[3]) #检查词汇表中的单词在文档中是否出现
print(returnVec)代码结果:

2)训练算法:从词向量计算概率
上面代码的功能是如何将一组单词转换为一组数字,接下来看看如何使用这些数字计算概率。现在已经知道一个词是否会出现在一篇文档中,也知道该文档所属的类别。现在将使用贝叶斯公式,对每个类计算该值,然后比较这两个概率值得大小。
计算思想是:先通过类别i(侮辱性留言或非侮辱性留言)中文档数除以总的文档数来计算概率p(ci),接下来计算p(w|ci),这里就要用到朴素贝叶斯假设。如果将w展开为一个个独立特征,那么就饿可以将上述概率写作p(w0,w1,w2...wn|ci)。这里假设所有词都相互独立,该假设也成作条件独立性假设,它意味着可以使用p(w0|ci)p(w1|ci)p(w2|ci)...p(wn|ci)来计算上述概率,这就极大简化了计算的过程。
下面函数的功能是:
a)计算侮辱性文章占总文章的比例
b)计算侮辱性文章中各个单词占侮辱性文章总单词的比例
c)计算非侮辱性文章中各个单词占非侮辱性文章总单词的比例
#朴素贝叶斯分类器训练函数
#trainMatrix 共n个数组,n为文章个数,每个数组是每一篇文章对应的词汇表数组 [0,0,1,0,1...0,0]
#trainCategory #n个文章的类别
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) #总文档数
numWords = len(trainMatrix[0]) #词汇表长度
pAbusive = sum(trainCategory)/float(numTrainDocs) #sum(trainCategory)计算为1的数目,计算侮辱性文章占总文章的比例
p0Num = ones(numWords); p1Num = ones(numWords) #初始化为1,p0Num 是非侮辱性文章各个单词出现数目,p1Num 是侮辱性文章各个单词出现数目
p0Denom = 2.0; p1Denom = 2.0 #初始化为2,p0Denom是非侮辱性文章单词总数,p1Denom是侮辱性文章单词总数
for i in range(numTrainDocs): #总文档数
if trainCategory[i] == 1: #第i篇文章是侮辱性的
p1Num += trainMatrix[i] #统计侮辱性文章各个单词出现情况
p1Denom += sum(trainMatrix[i]) #统计侮辱性文章单词总数
else: #不是侮辱性的文章
p0Num += trainMatrix[i] #统计非侮辱性文章各个单词出现情况
p0Denom += sum(trainMatrix[i]) #统计非侮辱性文章单词总数
p1Vect = p1Num/p1Denom #侮辱性文章各个单词出现比例
p0Vect = p0Num/p0Denom #非侮辱性文章各个单词出现比例
return p0Vect,p1Vect,pAbusive
#测试
listOPosts,listClasses=loadDataSet() #加载数据
myVocablist=createVocabList(listOPosts) #创建词汇表,所有文章里不重复的单词表
trainMat=[]
for postinDoc in listOPosts: #一次读取每一篇文章
trainMat.append(setOfWords2Vec(myVocablist,postinDoc)) #先将每篇文章转换成数字数组后加入trainMat
p0V,p1V,pAb=trainNB0(trainMat,listClasses) #计算各种比例
print("pAb:",pAb)
print("p0V:",p0V)
print("p1V:",p1V)代码结果:

现在已经准好构建完整的分类器了
3)测试算法:根据实际情况修改分类器
a)利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,即计算p(w0|1)p(w1|1)p(w2|1)。如果其中一个概率值为0,那么最后的乘积也为0.为了降低这种影响,可以将所有词的出现数初始化为1,并将分母初始化为2。
b) 另一个遇到的问题是下溢,这是由于太多很小的数相乘造成的。当计算乘积p(w0|ci)p(w1|ci)p(w2|ci)...p(wn|ci)时,由于大部分银子都非常小,所以程序会下溢出或者得不到正确的答案。一种解决办法是对乘积取自然对数。在代数中有ln(a*b)=ln(a)+ln(b),于是通过求对数可以避免下溢出或者浮点数舍入导致的错误。同时,采用自然对数进行处理不会有任何损失。
将上述代码中,最后改为取对数。
def trainNB0(trainMatrix,trainCategory):
...
...
p1Vect = log(p1Num/p1Denom) #侮辱性文章各个单词出现比例,然后取对数
p0Vect = log(p0Num/p0Denom) #非侮辱性文章各个单词出现比例,然后取对数
...现在已经准好构建完整的分类器了,测试一下效果:
#朴素贝叶斯分类函数
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
#测试函数
def testingNB():
listOPosts,listClasses = loadDataSet() #加载数据
myVocabList = createVocabList(listOPosts) #创建词汇表,所有文章中不重复的单词表
trainMat=[]
for postinDoc in listOPosts: #一次读取每一篇文章
trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) #先将每篇文章转换成数字数组后加入trainMat
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses)) #计算各种比例
testEntry = ['love', 'my', 'dalmation'] #测试输入数据
thisDoc = array(setOfWords2Vec(myVocabList, testEntry)) #转换成数字数组
print (testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)) #打印测试结果
testEntry = ['stupid', 'garbage'] #测试输入数据
thisDoc = array(setOfWords2Vec(myVocabList, testEntry)) #转换成数字数组
print (testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)) #打印测试结果
testingNB()代码结果:

4)准备数据:文档词袋模型
目前为止,我们将每个词的出现与否作为一个特征,这可以被描述为词集模型(set-of-words model)。如果一个词在文档中出现不止一次,这可能意味着该词是否出现在文档中不能表达某种信息,这种方法被称为词袋模型(bag-of-words model)。在词袋中,每个单词可以出现多次,而在词集中,每个词只能出现一次。为了适应词袋模型,需要对函数setOfWords2Vec()稍加修改,改为bagOfWords2Vec()。
下面的程序给出了基于词袋模型的朴素贝叶斯代码。它与setOfWords2Vec()几乎完全相同,唯一不同的是每当遇到一个单词时,它会增加词向量中对应的值,而不只是将对应的数值设为1。
#朴素贝叶斯词袋模型
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec现在分类器已经构建好了,下面我们利用该分类器来过滤垃圾邮件。
四,实例代码二:使用朴素贝叶斯过滤垃圾邮件
在前面那个简单的例子中,我们引入了字符创列表。使用朴素贝叶斯解决一些现实生活中的问题时,需要先从文本内容得到字符创列表,然后生成词向量。下面这个例子中,我们将了解朴素贝叶斯的一个最著名的应用:电子邮件垃圾过滤。
1)准备数据:切分文本
按空格切分字符
mySent='This book is the best book on Python or M.L. I have ever laid eyes upon.'
rst=mySent.split()
print(rst)代码结果:

使用正则表达式来切分句子,其中分隔符是除单词、数字外的任意字符创。
import re
mySent='This book is the best book on Python or M.L. I have ever laid eyes upon.'
regEx=re.compile('\\W*')
listOfTokens=regEx.split(mySent)
print(listOfTokens)代码结果:
![]() 去除空格,并将大写字母改成小写
去除空格,并将大写字母改成小写
import re
mySent='This book is the best book on Python or M.L. I have ever laid eyes upon.'
regEx=re.compile('\\W*')
listOfTokens=regEx.split(mySent)
rst=[tok.lower() for tok in listOfTokens if len(tok)>0]
print(rst)![]()
2)测试算法:使用朴素贝叶斯进行交叉验证
#函数功能,接受一个大字符串并将其解析为字符串列表
#该函数去掉少于两个字符的字符串,并将所有字符串转换为小写。
def textParse(bigString): #input is big string, #output is word list
import re
listOfTokens = re.split(r'\W*', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
#使用贝叶斯分类器对邮件进行自动化处理
def spamTest():
docList=[]; classList = []; fullText =[]
for i in range(1,26):
wordList = textParse(open('email/spam/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(1)
wordList = textParse(open('email/ham/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList = createVocabList(docList)#create vocabulary
trainingSet = list(range(50)); testSet=[] #create test set
for i in range(10):
randIndex = int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat=[]; trainClasses = []
for docIndex in trainingSet:#train the classifier (get probs) trainNB0
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(array(trainMat),array(trainClasses))
errorCount = 0
for docIndex in testSet: #classify the remaining items
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
errorCount += 1
print ("classification error",docList[docIndex])
print ('the error rate is: ',float(errorCount)/len(testSet))
#return vocabList,fullText
spamTest()代码结果:

欢迎扫码关注我的微信公众号
