0. 前言
使用梯度下降法对神经网络进行优化时,会由于初始值选取得不好而陷入局部最优解;而动量方法就可以对其进行改进。
1. 动量法
-
普通梯度下降法:
θ t + 1 ← θ t − η ∇ θ J ( θ t ) \theta_{t+1} \leftarrow \theta_t-\eta \nabla_{\theta} J(\theta_t) θt+1←θt−η∇θJ(θt)
-
动量法:
v t ← ρ v t − 1 − η ∇ θ J ( θ t ) v_{t} \leftarrow ρv_{t-1}-\eta \nabla_{\theta} J(\theta_t) vt←ρvt−1−η∇θJ(θt)
θ t + 1 ← θ t + v t \theta_{t+1} \leftarrow \theta_t+v_{t} θt+1←θt+vt
ρ ρ ρ 表示历史梯度的贡献率
主要思想:更新参数时将历史梯度信息考虑进去;
动量是惯性的来源,即通过 t − 1 t-1 t−1 时刻和 t t t 时刻来对 t + 1 t+1 t+1 时刻产生共同的影响,相当于引入了一种惯性,这在一定程度上避免陷入局部最小值,落入以后大概率会被惯性甩出来
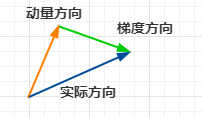
上图中对于下一步的走法就是,动量的方向和梯度的方向相结合。
-
Nesterov动量法
v t ← ρ v t − 1 − η ∇ θ J ( θ t + ρ v t − 1 ) v_{t} \leftarrow ρ v_{t-1}-\eta \nabla_{\theta} J(\theta_t+ρ v_{t-1}) vt←ρvt−1−η∇θJ(θt+ρvt−1)
θ t + 1 ← θ t + v t \theta_{t+1} \leftarrow \theta_t+v_{t} θt+1←θt+vt
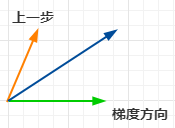
在动量法的基础上改动的部分是梯度那里,即不再是关注当前的梯度,是先根据动量的方向走一步,再在此处看梯度方向,也就是在计算梯度时向前多看了一步,用图来表示就是: