简介
pandas是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构。
pandas主要的两种数据结构为Series和DataFrame,分别用于处理一维和二维数据。
Series
Series 是一种类似于 Numpy 中一维数组的对象,它由一组任意类型的数据以及一组与之相关的数据标签(即索引)组成。
构造
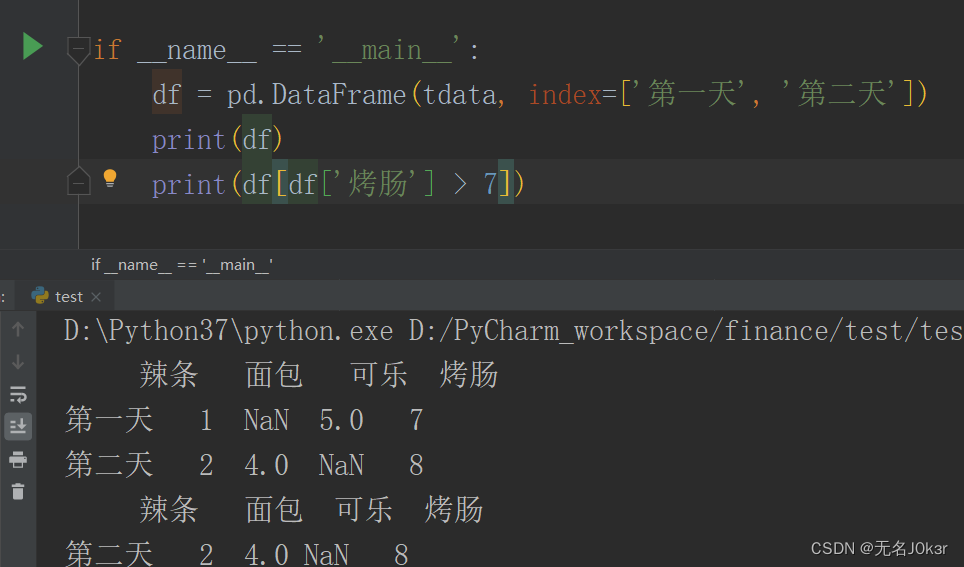
abcd为索引,1234为数据
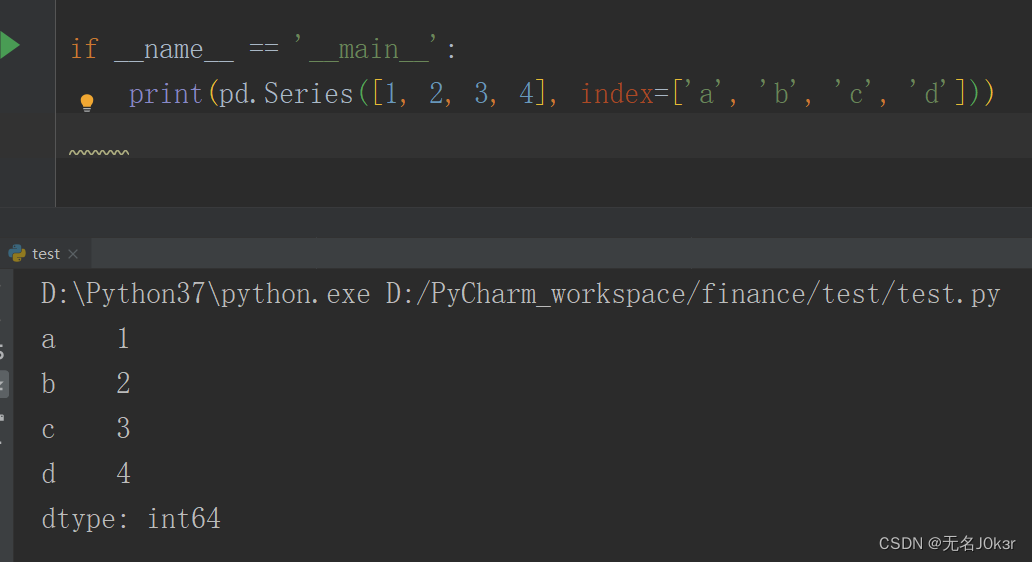 也可以传入字典构造一个Series
也可以传入字典构造一个Series
DataFrame
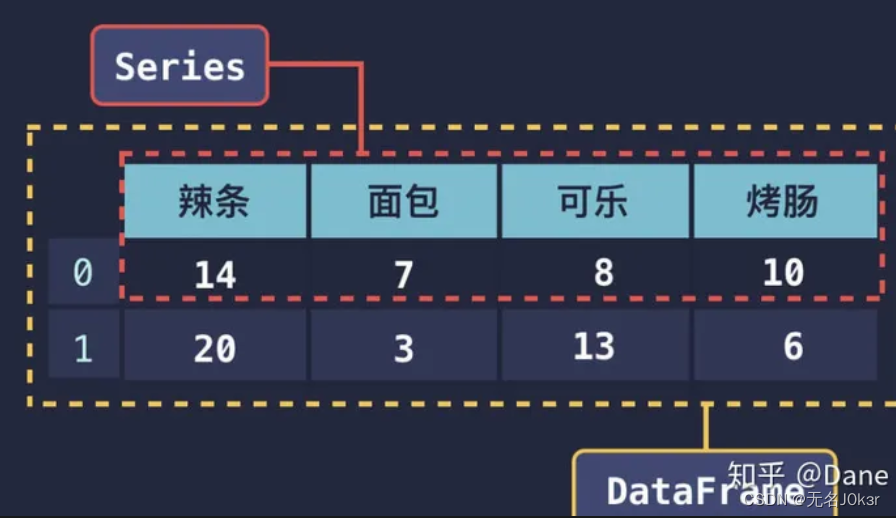
DataFrame是类似表格的二维数据,每一行每一列都是一个Series。
构造
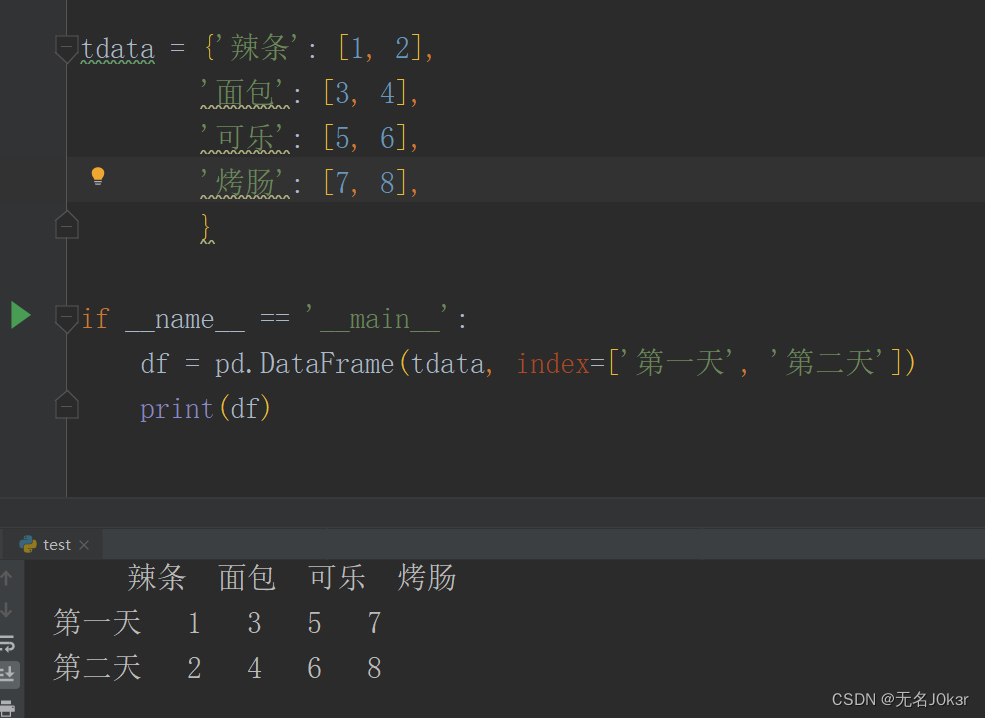
可传入一个由等长列表组成的字典,即字典里每个value都是列表且长度相等。
列的查改增删
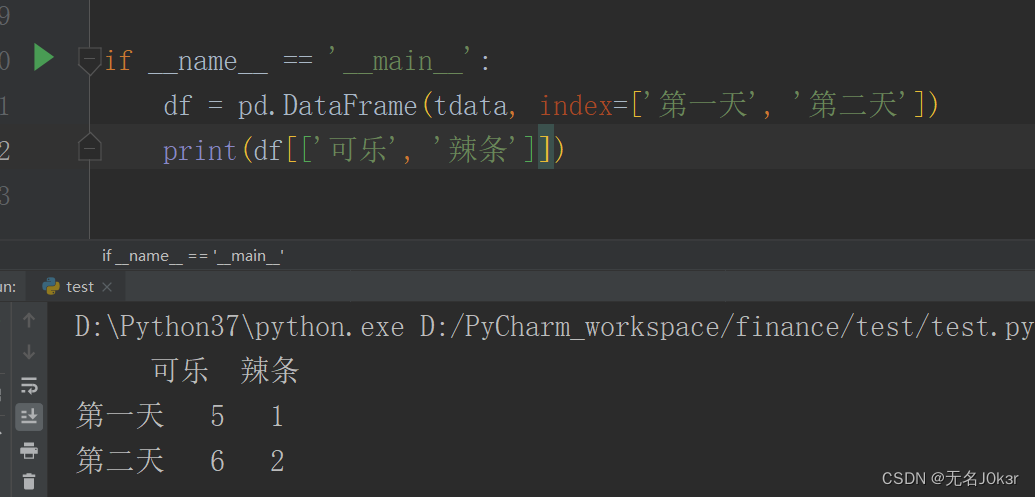
查
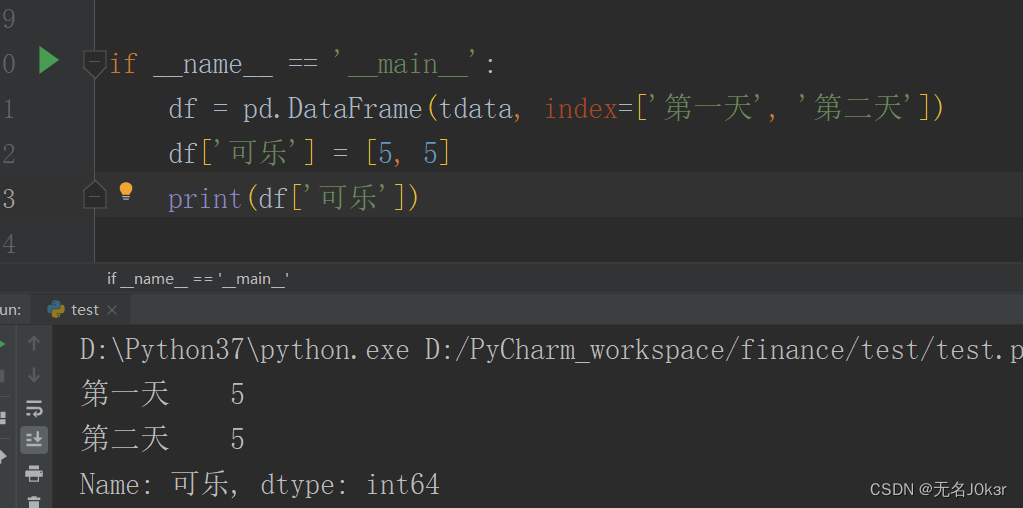
改
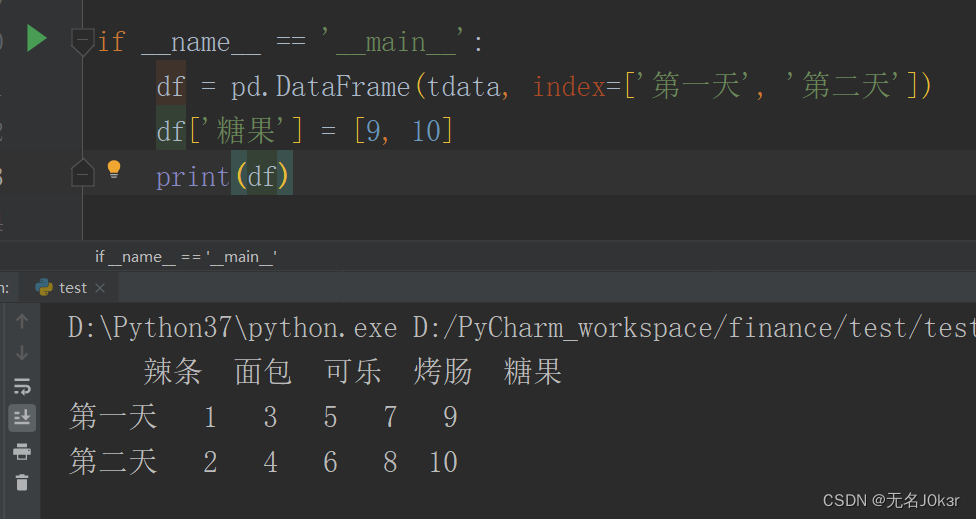
增
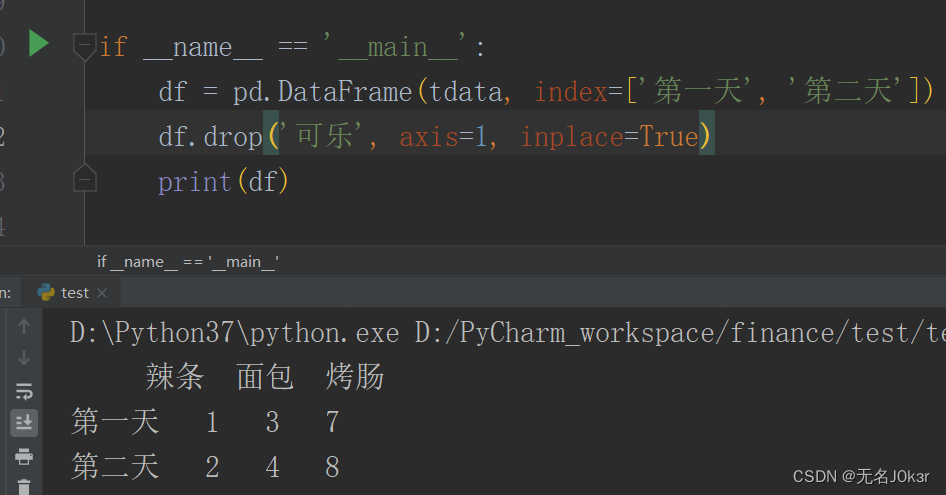
删
axis=1意为操作列,inplace指是否修改原数据
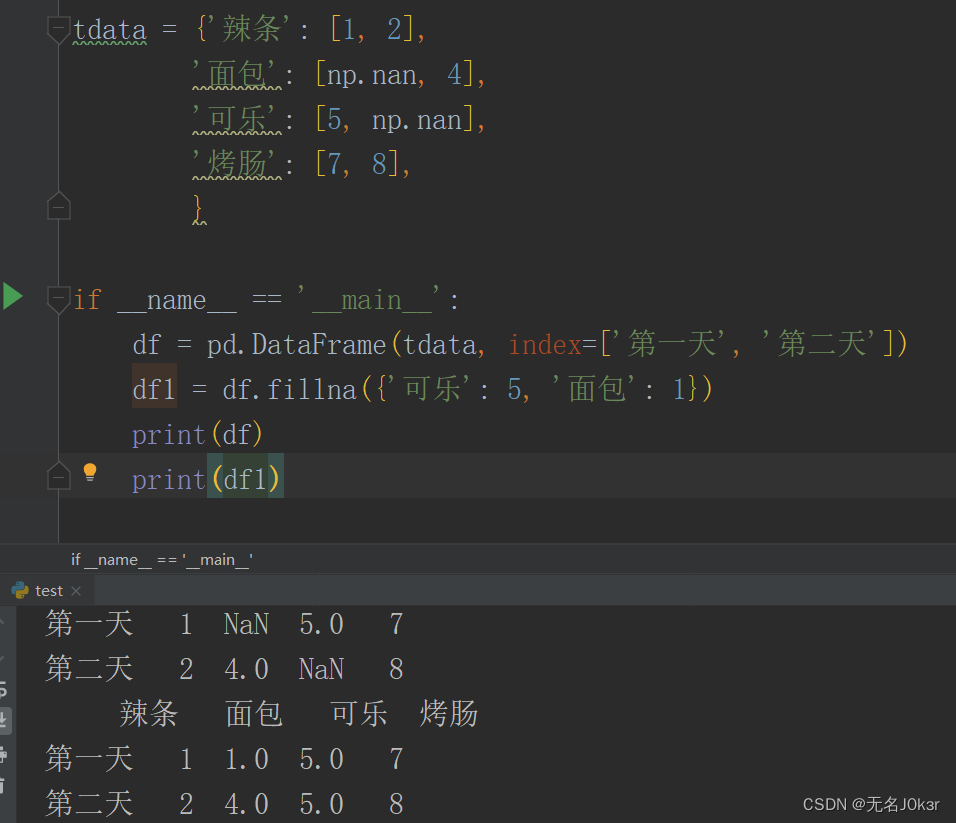
填充默认值
用loc与iloc取数据
iloc:基于位置,用行号、列号进行索引,i 可以看着 int,因此 iloc 只能用整数来索引,例如data.iloc[0:2,:]
loc :基于标签,用行名、列名进行索引,数据的index经常为整数,因此 loc 的使用范围要远高于iloc,loc可以使用整数切片、名称(index,columns)索引、也可以切片和名称混合使用。例如:data.loc[0:5,‘row1’:‘row2’]

Pandas中iloc、loc、ix、直接索引的用法和区别
条件选择