导入库
import pandas as pd
from rdkit import Chem
from rdkit.Chem import rdMolDescriptors
from rdkit.Chem import Draw
import numpy as np
import warnings
warnings.filterwarnings("ignore")载入数据
df = pd.read_csv('smiles.csv')将smiles转换为RDKit的mol对象
df['mol'] = df['smiles'].apply(lambda x: Chem.MolFromSmiles(x))绘制结构
Draw.MolsToGridImage(df['mol'][:5], molsPerRow=5, legends=list(df['smiles'][:5].values))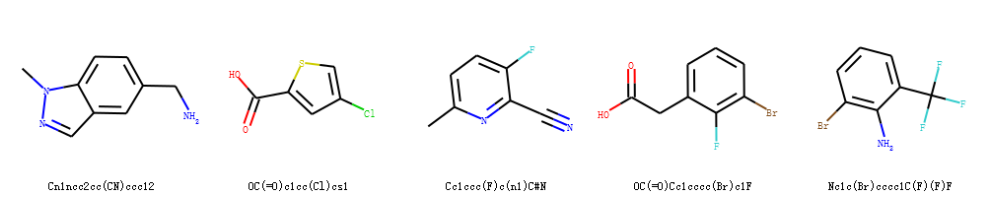
定义获取分子中典型原子的函数
def number_of_atoms(atom_list, df):
for elmt in atom_list:
df['num_of_{}_atoms'.format(elmt)] = df['mol'].apply(lambda x: len(x.GetSubstructMatches
(Chem.MolFromSmiles(elmt))))
number_of_atoms(['C','O', 'N','P', 'S'], df)
# Get the number of aromatic and aliphatic rings
df['num_of_arom_rings'] = df['mol'].apply(lambda x: rdMolDescriptors.CalcNumAromaticRings(x))
df['num_of_aliph_rings'] = df['mol'].apply(lambda x: rdMolDescriptors.CalcNumAliphaticRings(x))
# Check the columns
df.head()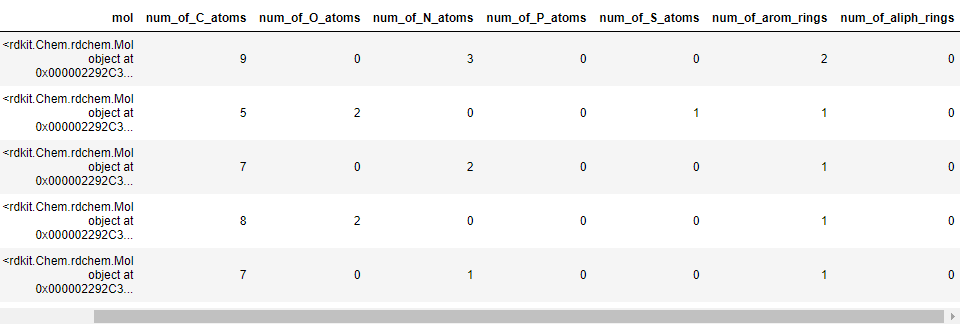
分子库中所有分子所含典型原子数目
print("number of molecules containing Sulfur: {}".format(
df['num_of_S_atoms'].astype(bool).sum(axis=0)))
print("number of molecules containing Phosphorus: {}".format(
df['num_of_P_atoms'].astype(bool).sum(axis=0)))
print("number of molecules containing Nitrogen: {}".format(
df['num_of_N_atoms'].astype(bool).sum(axis=0)))
print("number of molecules containing Oxygen: {}".format(
df['num_of_O_atoms'].astype(bool).sum(axis=0)))number of molecules containing Sulfur: 22928
number of molecules containing Phosphorus: 3
number of molecules containing Nitrogen: 99862
number of molecules containing Oxygen: 94382